Tableauで「困って・調べて・解決した」ちょいTIPS(2021年3月)
tableauをいじっていると、どうしてもここがしっくりいかないという点が細々とでてきます。 そこで今月つかったりWEBで探したテクニックをご紹介したいと思います。
TIPS「ドーナツチャートでのKPI表示方法」
KPIをわかりやすく表示する方法は色々あると思いますが、最近個人的にお気に入りの表現方法として「ドーナツチャートでの表示」があります。
円グラフで多くのデータを表示するのはとても見栄えが悪く、近年敬遠される傾向がありますが、1つのデータの割合を表す場合、円グラフは視覚的にもまだまだわかりやすい表示方法で真ん中を白くくり抜いているドーナツチャート(大体がその中にKPIとなる数値を入れる)はとても優れた表現方法と思います。
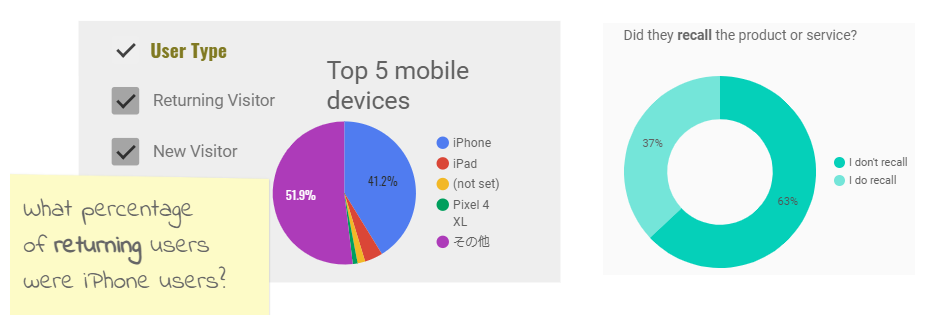
左図が円グラフでのデータ表示、特に割合が低いデータを把握しづらい (参照Welcome to Data Studio! (Start here)) 右図がドーナツチャート、真ん中を白抜きにすることで見栄えが軽く見え割合が目視できる (参照 Google Data Portal Overview)
難度:★☆☆ 用途:指標をドーナツチャートで表示したい場合 方法:円グラフを2重軸を使い重ねる 参考:knowledge.insight-lab.co.jp
このチャートをKPIとして表示する場合のスタンダードな形は以下が参考になると思います。
 Viz バラエティショー: 本当の価値があるドーナツチャート
Viz バラエティショー: 本当の価値があるドーナツチャート
また実案件では指標がマイナスの場合もあると思います。その表現方法の応用としては以下のような使い方ができます。

上記に関しては色々とノウハウがありますので詳細は伏せますが、ご要望ございましたら是非案件のご相談いただければ幸いです。

データサイエンティストって何?GRI社員の素顔に迫る!
こんにちは、分析官の早川です。 弊社では、現在2022年度新卒の採用をはじめております。 その中で、学生さんの多くから、データサイエンティストとは?データサイエンティストにはどんな人が向いているか?GRIにはどんな人材が多いのか?必要な技術は何か?といった質問を多く受けます。 そこで、博士新卒1年目の私が実際に一年働いて感じた、生のデータサイエンティストの声をお届けしようと思います。 業界研究等の参考にしつつも、興味を持っていただけた方は、ぜひ一緒に働きましょう。
大きく二つ、 1. ジェネラルに データサイエンティストの仕事の話 2. 弊社が実際どんな人材で構成され、活躍しているかの話 でお届けします。
データサイエンティストって何?
データサイエンティストとは?
現在ニーズが急速に高まっている職業データサイエンティスト。 一言で言えば、データのスペシャリストです。
IT技術が急速に進化を遂げ、様々なデータがストックできる時代になりました。 データは多岐に渡り、それを元に意思決定したり、新たなイノベーションを起こそうというムーブメントが日本に限らず、世界全体で注目を集めています。 これまで人間が考え、起こしていた行動が、データとしてストックされることにより、科学的に根拠を持って複雑に絡み合った人間活動の理解が進んできているからです。 ただ、そのデータの利活用には、高度な数学や、金融、ビジネスへの理解、そもそもデータをストックするためのシステムの理解や計算機(コンピュータ)の理解 等々、幅広い知識や経験が必要であり、現在データサイエンティストの需要が高まっているわけです。
具体的にどんなお仕事をしているの?
データサイエンティストの仕事は、データに関わることはなんでもする、というのが答えです。 データを利活用するといった時に、大きな流れとしては、
- データを集める
- データを分析できるように加工する (ETL)
- データを分析,可視化
- 分析結果を元に意思決定をサポートする
の上記4つがメインになると思います。
1. データを集める
データがなければ私たちの仕事ははじまりませんが、データを集めるだけでも相当に大変です。 データの解析は、データの数が多ければ多いほど精度が上がる傾向にあるので、できるだけ多くの情報を正しく、素早く、利用しやすいように集める必要があります。 また、経済活動は常に変化し続けているため、一時的なデータの収集ではなく、継続的に集める必要もあります。
これらの要件を満たすためには、データを集めてストックするためのシステムは必須です。 データエンジニアの領域に近いですが、データサイエンティストもその設計に携わらないと、データはあっても解析ができない何かになってしまいます。
ここでのデータサイエンティストの役割は、
最終的なアウトプット(解析結果)のために必要なデータ収集システムを、データエンジニアと協力して構築し、自動的に集める
だと考えてます。
2. データを分析できるように加工する (ETL)
データを利活用する際に、必ず ETL という作業が必要になります。 ETLは、 Extract, Transform, Load の頭文字を取ったもので、 データを抽出、変換し、分析用のプラットフォームへ流す、という意味です。
例えば、ECサイトのデータを考えてみます。 まずは、注文情報や、顧客情報といったデータを、データを格納しているサーバーから必要な分だけ抽出します (Extract)。
注文情報や、顧客情報は別々のデータとして保存されることが多いため、これらを関連づけ、新しいデータを作ります。 またその中で、欠損値や必要のなさそうなデータを落とします (Transform)。 この作業で、AIでの精度が落ちたり、可視化の際に余計なリソースを使ったり、予期せぬ不具合を起こすことを事前に避けます。
最終的に綺麗にしたデータを可視化や解析をするBIツール等に流し込みます (Load)。
ETL作業は、データを収集段階とも密接に関わりがあるので、データエンジニアの仕事に近い部分もありますが、データサイエンティストも必須だと思います。 最終目標のために、必要な重要なデータを落とさず、綺麗にするという作業は、分析作業や最終的な目標を見据えないと大きな失敗を招くためです。 現在では、BIツールでこの部分もフォローできるようになっているので、データサイエンティストも積極的に取り組むべき部分です。
ETL作業を終えて、やっとデータ分析、可視化です。
3. データ分析、可視化
データサイエンティストの花形です。 クライアントの事業を理解し、データを用いて課題を発見する。その課題を克服できそうな糸口をデータから見つける。 それを一目でわかるように可視化する。 単純に分析するだけではだめで、必ず大きな課題があってその課題の発見や、解決のためのデータの分析です。
分析と言ってもやり方は多岐に渡り、Python, R等で統計的な処理をする場合もあれば、AI等で予測をつけることもあれば、時にはForecastflow のように自動機械学習ツールに頼ることもあります。 最近だと tableau をはじめとするBIツールも主流になっています。
ECサイトで例えてみます。 自動化されたECサイトのデータは毎日流れてきますが、それを毎日可視化する作業を手でやっていては無限にリソースを食ってしまいます。 そこでBIツール (例えば tableau のような可視化ツール) を用いて、日々の売上、顧客情報等 ECの現状確認できるダッシュボード(可視化、分析結果確認の雛形)を、データサイエンティストが作成します。 このダッシュボードに、ETLされたデータを読ませるシステムさえ作っておけば、データサイエンティスト以外の人でも簡単に、毎日ECの売れ筋や人の構成を確認して、素早く施策のヒントを得ることができます。 顧客に合わせて、おすすめの商品を自動で剪定するAI を用意するのであれば、レコメンド用のAIモデルをデータサイエンティストが作ることになります。
ただなんとなくアウトプットを出すのではなくて、ビジネスを理解した上で、重要になりそうな部分を剪定して可視化する、モデルに組み込む。 データが扱えない人へ正しく、データの意味を翻訳する (もしくは、データの意味を自動翻訳するシステムを作る)
データサイエンティストの腕の見せ所です。
4. 分析結果を元に、意思決定をサポート
データサイエンティストとして、見落とされがちですが、一番大事な部分になります。 データを分析した結果を確実にクライアントに伝え、その結果を元に次の意思決定をサポートする。 ここまでこなして一流のデータサイエンティストであり、理想像です。 マーケティング企画、事業企画等々、データの分析結果を実利に起こせるデータサイエンティストこそ、現代で一番求められています。 そのためには、ビジネスやドメイン知識は必須で、クライアントととのコミュニケーションも欠かせません。 議論の中で新しい課題を発見したり、さらに新しい切り口を探すことも求められます。
データサイエンティストは、データを解析するだけと思われがちですが、実際にはクライアントと直接話をする機会も多いです。 むしろここが一番重要です。 データから得られた知見を正しく伝え、課題を解決し、さらにその先のビジネスへつなげる。 ここまでで一流のデータサイエンティストだと感じています。
データサイエンティストに必要な技術は?
データサイエンティストがやる業務をざっくりとまとめましたが、これらを総合すると、必要な技術は多岐にわたると伝わったかと思います。
データを触る技術的には、
統計学、AI技術等を理解できる数学力
可視化技術 ( BIツール)
その他、必要な考え方や知識
課題発見力、解決力
ビジネス理解
デザイン知識 (正しく人へ伝えるための方法論、思考術)
コミュニケーション能力
大まかにあげるとしたらこの辺でしょうか。 データを触る技術だけでデータサイエンティストが重宝されていた時代は終わりを迎え、現在では後者も必須です。
GRIはどんな会社? 人材は?
データサイエンティストになるために必要な技術は伝わったかと思いますが、データで新たな事業を開発していくカンパニー。である弊社がどうなっているのかを人材、働き方、業務内容という観点で紹介します。
1. 分析官のほとんどが、理系院卒!
高度な数学力や、可視化能力が試されるので、弊社には理系の人材がほとんどです。 そして、そのほとんどが大学院修士課程もしくは博士課程を修了しています。 出身大学で見ると、東大、東工大、筑波、東京理科大あたりが多い気がします。
理系院卒が重宝されている理由としては、課題発見、必要な解決策の提示、実行、クライアントに伝える力と言った部分が、大学院生活でかなり鍛えられているからです。 研究のプロセスと一緒です。 弊社では、物理学出身の人間が多いですが、素粒子物理、宇宙物理、高分子化学、ウイルス、生物行動、画像認識、コンピュータサイエンス等々、様々な分野の人間が集まっています。 私も宇宙物理から転校してきた博士新卒です。 特に最近はAIと物理学のシナジーもかなり議論されているので、この部分はかなり弊社の強みだと思います。
入社前に持っているスキルとしては、
プログラミングの基礎的な知識
数学力
英語力
情報収集力 (最新の論文を追える、トレンドを知れる、課題解決のための検索力)
人へ正しく伝える力
この辺りを自然と身につけている人が多いと感じています。
2. 新しい技術、知識を得ることが大好き
院卒が多いこともあり、気になったことはとことん調べたり、論文を読んだり、本を読んだりがデフォルトです。 雑談等でも、読んだ本の内容を議論したり、レビューしあったりもよくしています。 思考実験的なことも好きで、フェルミ推定的なことはふとした雑談からもよく発生します。 雑談というか、本格的にヒートアップして議論になることもしばしば。
3. 芸達者, 多趣味
データを追求することは、何か実際に起きていることを深掘りしていくことになります。 そうすると、これまでの人生で何かに熱中した人が多く、活躍もしていると感じてます。 例えば、中高や大学での部活動等で結果を残していたり(県大会上位や上位大会出場等)、書道等、習い事で段位を持っている人も多く、数カ国語話せる人もいます。
趣味も多岐に渡り、美術館巡りや楽器の演奏、アニメ視聴等々。 若手男子社員は、筋トレがブーム!
また弊社では、部活動制度があり、二人以上で自由に部活を作って活動ができ、経費も落ちます。 これまでの趣味を深堀するも、新しいものに挑戦するでも、自由にできるので、果敢に色々なことに挑戦できると思います。
ちなみに私は、中高の部活動で本気で弓道をやっていたので、ぜひ弓道経験者いましたら一緒に部活動しましょう。笑
4. オン、オフの切り替え
仕事を長く楽しく続けるためにはオンオフの切り替えはとても重要だと個人的に考えています。
リラックスできるお昼休み
ランチは会社周りでトークしながら食べたり、お昼寝休憩も30分認められています。
残業、休日出勤 ほぼなし!
忙しい時期はともかく、残業を長くやるというのは弊社では好まれていません。 7時半ともなればほとんどの人が退社してます。 休日出勤は基本認められていないです。
完全フリーな休日
土日祝日、お盆、年末年始、もちろん有給も。 それぞれがプライベートを楽しんでます。 メール、スラック全部無視でOK!
限られた時間で効率をあげて仕事をする。 オン、オフがかなりはっきりしている会社だなと感じてます。
5. リモートワーク? オフィスワーク?
COVID-19 の流行以前より、弊社では裁量労働、リモートワークが認められております(新入社員を含め)。 それぞれが自分の時間で、やりやすいやり方で仕事を進めています。 現状、オフィスは毎日 5-6人程度で、出社率としては、2割弱と言ったところでしょうか。
6. プロジェクトはどう進める?
1案件 2-3人で、2-3ヶ月単位で進めることが多いです。 マネージャー + 分析官 + サポート と思っていただけたら。
データの分析では、その都度新しい課題が見えてきたりすることも多いので、短いスパンで、的を絞ってこなすことが多いです。 その中でさらに、必要があればまた新しく2-3ヶ月追加で取り組んでいくという形をとっています。 また、1人月全てを1案件に当てることは少なく、0.5人月 * 2案件 で並行して進めることが多いです。
7. 一年目の仕事は?
1ヶ月ほどの研修を終えた後は、それぞれ得意分野に合わせて案件にサポートとしてアサインされていき、OJT で経験を積んでいきます。 人にもよりますが、半年くらい経ってからは一人前扱いで、一年目の後半は、案件に一人月でアサインされて案件をこなしていきます。 このスピード感と、経験はなかなか他社では経験できない弊社にしかできない強みだと考えています。 もちろん大変なことも多いですけどね笑
案件としては、大まかに開発系の案件と、BIを用いたコンサルティングに分かれますが、個々の特技やバックグラウンドに応じてアサインされます。 私はバックグラウンドとしては、宇宙物理の大学院で、物理の基礎方程式からモデルを立ててシミュレーションをしていたので、分析やAI, BIとは全く馴染みがありませんでした。 しかも、プログラミングはFortran とC をかじっただけというかなり特殊な状態でのスタートでした。 一年目の仕事は、まずはtableau を用いたデータの可視化や分析から始まり、tableau server の構築(EOL対応), Python でのAI 開発などデータサイエンティストに必要な案件は一通り経験させてもらいました。 他の新卒一年目の同期は、AI関連の研究室所属だったこともあり、開発系の案件で、画像認識系や自然言語処理と言った部分での基盤構築の案件にアサインされていました。
8. どういう人が評価される? 会社として目指しているものは?
個人の成長に赴きを置いているため、年に二回にMBO計画で、個々の意見を尊重して、アサイン計画を組まれたり、サポートを受けられます。 成果ももちろん大事ですが、できることを増やし、成長していくことが評価されるので、個人に厳しく成果を求められることはないです。 私も一年間でかなりできる幅と知見が広がり、これは弊社にしかできない経験だと誇りに思っています。
会社全体としては、とにかく面倒見がいい場であり続けたいとしています。 できる人ができない人をサポートして、成長を促し、成長した個人がまた下の世代、もしくは独り立ちして事業を起こしていく。 そういったことを一番の喜びとして、全員が意識をして仕事に取り組んでいます。
9. 結局、GRIはどういう会社なんだ!?
新卒の面談の中で多く聞かれる質問ですが、一年働いた私の率直な印象をまとめておきます。
「個性豊かで、
スーパーマンなデータサイエンティストたちが、
データで新たな事業を開発していくカンパニー。 」
データ解析会社の多くはエンジニアリング色が強く終わってしまい、ビジネス的な視点を欠いた解析だけで終わってしまうことが多いです。 コンサルファームでも、クライアントの目前の問題は解決しても事業に繋がる会社は多くありません。 データ基盤の整備から、事業に繋げるまでが、少人数で素早くこなされていく会社は弊社だけだと思います。 それらを確実にハイクオリティでこなしていけるスーパーマンがたくさんいます。 そして、スーパーマン同士のシナジーで成長し、さらに強烈な個性を発揮していると感じてます。
終わりに
データサイエンティストは必要な技術が多岐に渡り、それに伴って、弊社の人材もかなり個性が強い集団だということ、少しはお伝えできたかと思います。 データサイエンティストはその人の特技に応じて、社会への貢献の仕方も多岐に渡るので、特技一つだけでも大きく貢献はできると思います。 ただ、弊社ではそこで止まらず、常に挑戦して、新しい技術を得ることで、得たものの組み合わせでさらに強い個性を生み出しています。 その個性は、ひいては生きがいにつながり、人生を豊かにするものにもつながると思います。
得意なものを増やして成長できる、強い個性を広く受け入れられる弊社でぜひ一緒に仕事してみませんか? 強烈な個性をもった人材、歓迎です!
分析官 早川朝康
雑記: 東京タワーと内藤多仲先生の言葉
こんにちは。初めまして。新卒1年目の早川です。 私は大学院で宇宙物理学で博士号を取り、2020年4月からデータサイエンティストとして、働いています。
弊社のブログでは、技術的な話やビジネスに関することが多いですが、今回は弊社のオフィス周りに目を向けて記事を書くとします。 毎日なんとなく過ごしていると、身の回りのことを意外にも何も知らないということが結構あります。 そこで、私たちがオフィスから毎日見ている東京タワーにスポットをあてて、少し余談を。
東京タワー
弊社オフィスは、芝公園の近くにあります。地理に詳しい方はピンと来るかもしれないですが、東京タワーの足元です。 東京タワーは、1958年に世界一の高さを誇る電波塔として建設され、2011年 東京スカイツリーが建設されるまで、主要な電波放送の発進基地と利用されました。 また併設された展望台は、観光名所の一つとして知られ、令和時代に入ってもなお年間300万人以上の方が訪れています。 ところで皆さん、この東京タワーはどなたが建設されたかご存知でしょうか?
耐震構造の父 内藤多仲先生
東京タワーの設計者は、耐震構造設計の父とも呼ばれる内藤多仲先生です。 山梨県南アルプス市 (旧中巨摩郡榊村)出身、生涯に渡って、耐震構造設計の研究や、電波塔等の建造物建築に携わりました。 有名な話として、耐震構造設計への発想は、"荒海でも持ち運んだトランクが潰れずに残っており、そのトランクの中には間仕切り, 外は縄で縛られていた" ことから得られたと言われています。 当時の内藤先生の構造設計は相当に精緻なもので、60年以上が過ぎても凛として立っている東京タワーはそれを物語っています。 東京タワー以外にも、国内主要な電波塔(さっぽろテレビ塔, 博多ポートタワー等)、早稲田大学 大隈講堂, 新宿区役所、山梨県庁舎本館なども手がけています。
積み重ね 積み重ねても また積み重ね
内藤先生の生まれ故郷山梨県南アルプス市ですが、私の故郷でもあります。 内藤先生の信条や言葉は地元で語り継がれており、特に
積み重ね 積み重ねても また積み重ね
という句は地元の多くの人の支えにもなっている言葉です。 塔を立てるときと同じように、一つ一つのことを着実に丁寧にこなし完成させる。 日々の努力を怠らず、一つ一つ確実にこなして成長し、彼岸へ登りつめる。 仕事をしていく上でも、日々の日常生活をする上でも非常に大切な気概だと思います。
終わりに
データサイエンス業界はとても流れが早く、その技術や事業はどんどん深く、広くなっており、目指すものも盛大になってきています。 一方で、データを扱う多くの作業は地道なものも多くあります。 小手先だけで大きな目標を見失うこともあれば、大きな目標のために小手先が疎かになることもあります。 新卒1年目も終わりの節、初心に戻り、高登彼岸を目指したいものです。
弊社も大きなものを目指して、毎日成長を続けております。 一緒に積み重ね、大義を成し遂げたい方、ぜひ私たちと一緒に働きましょう。 お会いできるのを楽しみにしてます。
参考
分析官 早川朝康
連合学習によるプライバシー保護と利便性を両立した新しい機械学習システムのカタチ
深層学習が表舞台に登場してから、今年(2021年)で 9年 になるでしょうか。2012年のILSVRCという画像認識のコンペティションで、深層学習は2位以下に圧倒的な大差をつけて優勝しました。冬の時代を乗り越え、ニューラルネットワークが機械学習の中心に返り咲いた瞬間でした。
ILSVRCとは?
Stanford大学のLi Fei-Feiさんが中心となって管理する画像データベース ImageNet を利用して行われる画像認識タスクのコンペティションです。
www.image-net.org
深層学習システムはすでに至るところに社会実装されていて、例えば顔認識や音声認識、自動運転、画像・動画・文章などのクリエイティブの自動生成などはすぐに思いつきます。深層学習を始めとしたAIシステムはこれまでのヒトの仕事の一部を自動化することに成功していますが、まだまだ課題はあります。その中の一つにプライバシーの問題があります。
「鏡よ鏡、世界で一番美しいのは誰?」

一昔前であれば、ヒトの問いかけに的確に答えを返してくれる鏡なんておとぎ話でしたが、深層学習と安価で高性能なハードウェアが充実している2021年現在では、もはや1万円以下のリーズナブルなお値段で実現可能です。ただし、プライバシーの問題を解決しない限りはDIYの世界でとどまってしまいそうです。
DIYスマートミラー
例えば、Raspberry Piという小型PCで開発する場合は以下の記事が参考になります。
raspida.com
従来の鏡は今そこにいるありのままの自分を映すだけでしたが、各種センサーや深層学習を応用することで、鏡は将来を教えてくれたり、なりたい自分を指し示してくれる装置になります。
- 「鏡よ鏡、今日の天気は?」という問いかけで、気象情報やその日のおすすめの服装などをレコメンド
- 美容室に設置し、自分に似合う髪型をレコメンド
- ダンスの先生の動きをトレースし、自分との違いを教えてくれる
- 赤外線センサーを搭載することで、熱がないかどうかや、体調に異変がなさそうかを日々簡易チェック
スマートミラーは他にも色々応用はできそうですし、鏡だけではなくほかの身近な道具をスマートIoT化することでイノベーションが生まれそうな予感もあります。身近であるほどインパクトは大きいですが、その分、プライベートなデータを扱う必要がでてきます。
深層学習を始めとした機械学習システムが行っていることは、結局の所、過去の訓練データから入出力のパターンを抽出するということにつきます。特に深層学習のアーキテクチャは複雑で、何千ものパラメータをもっともらしく最適化するためには大量のデータが必要になります。そこで、ユーザーの行動履歴や画像ファイルなどを日々収集する仕組みが重要になるわけですが、現在のシステムの多くは、データは中央集権サーバーに集約して管理されています。機械学習モデルが直接参照するのは特徴量と呼ばれる生データとは異なる構造のデータで、ある程度プライバシーに配慮されたデータですが、特徴量の作成は何度も試行錯誤する必要があるタスクなので、異なるレイヤーで生データも保持されることが多いです。(もちろん、直接個人と紐づく可能性があるデータは非常に厳重に管理されていることは言うまでもないですが、一応付け加えておきます。)
自動車の運転データなどは企業に保持されてもそこまで拒絶反応はないかもしれませんが、例えば鏡に映った自分の姿を日々収集された場合はどうでしょうか?アパレルショップや美容室、ダンス教室などのパブリックな鏡であればギリギリ許容範囲の人もいるかもしれませんが、多くの人は自宅には設置したくないのではないかと思います。つまり、AIを生活のすみずみまで浸透させてスマートな社会を実現するには、プライバシーに配慮することが必要不可欠となります。
このような課題を解決するために、2017年にGoogleから連合学習(Federated Learning)という手法が提案されました。これは、従来のデータを中央集権的に集約・学習する機械学習システムとは異なり、システムの末端の端末(エッジ)で完結するアーキテクチャになるのがポイントで、ユーザーはプライベートなデータを企業のサーバーに送信しなくとも、機械学習システムの恩恵を得られるようになります。
連合学習(Federated Learning)
連合学習のスキームでは、中央サーバに親モデルを保有し、各エッジ端末に配布するところから始まります。配布されたモデルは各エッジのデータを利用して訓練・推論を行います。これだけでは親モデルは一向に改善されないので、訓練フェーズにて更新されたパラメータのみが各エッジから中央サーバに戻してもらいます。パラメータの差分のみから親モデルを改善する手法がいかに賢いかがパフォーマンスを左右します。
ai.googleblog.com
連合学習は、2022年に到来するクッキーレス時代とも深い関わりがあります。クッキーはWeb上でユーザを識別するデータとして広く利用されてきましたが、EUでは2018年にEU一般データ保護規則(GDPR)でクッキーは個人情報であると明確化され、EU域内の個人からクッキーを取得する際にはユーザに明示的に同意を得ることが義務付けられました。このような背景から、Googleは2022年にChromeのサードパーティークッキーのサポートを終了すると宣言し、広告業界には非常に大きなインパクトを与えました。Webの収益モデルとして広告は非常に大きな割合を占めるわけですが、これまでクッキーを利用してユーザを識別してターゲティングを行う手法も多く、代替案なしにクッキーを廃止することで広告事業主の広告収益が平均52%減少が予想されるとGoogleは報告しています。そのため、各社ファーストパーティクッキーの見直しやID統合などの取り組みも活発になっています。一方でGoogleは、ユーザのプライバシーを保護を前提としたWebエコシステムの構築を目指すプロジェクトPrivacy Sandboxを発表しており、その目玉のひとつにFLoC(Federated Learning of Cohorts)というAPIがあります。これは連合学習により行動履歴からユーザをコホート(群れ)に分類し、ターゲティングはそのコホートをベースに達成するスキームになっており、Googleの調査では既存の広告ターゲティングとほぼ同等のパフォーマンスを達成できるとしています。
プライバシーの問題とAIがもたらす利便性のバランスをとる動きは今後より活発になりそうです。現時点では連合学習の仕組みは世の中に浸透していませんが、5年後には「セキュアAI」などのサービス名で連合学習モデルを構築するためのプラットフォームが続々と出現しているのではないかと個人的には思っています。
Privacy Sandbox
www.chromium.org
大友
BigQueryのユーザー定義関数(UDF)を使ってみた
こんにちは!
アナリストのMです。
日々の業務でBigQueryに触れる機会が頻繁にあるのですが、 恥ずかしながら最近になってユーザー定義関数(UDF)なるものの存在を知りました(汗)
ちょっと使ってみて個人的にはかなり便利だと感じたので、 本記事ではUDFを使用したことがない人やそもそも何それ?状態の方向けにUDFの利便性や実装方法を簡潔に共有したいと思います。
ユーザー定義関数(UDF)とは?
ユーザー定義関数(UDF)は読んで字のごとく、ユーザー独自で定義する関数です。
頻繁に行うやや複雑な処理をSQLかJavaScriptを用いてUDFとしてあらかじめ関数化しておくことで、
以下のようなメリットが見込めるようになります。
・コードがすっきりする
・コーディングミスが減る
UDFには、1つのクエリで一時的に利用できる一時UDFと複数のクエリで再利用可能な永続UDFが存在します。 次節以降ではSQLを用いたそれぞれのUDFの実装方法を紹介します。
デモ用テーブルの準備
下記クエリを実行し、日付が3つのカラム([date_year],[date_month],[date_day])に分かれて整数型として格納されているテーブル"demo"を作成しておきます。
-- 空テーブルを作成
CREATE OR REPLACE TABLE `[プロジェクト名].[データセット名].demo` (
date_year INT64,
date_month INT64,
date_day INT64
);
-- 空テーブルにデータをインサート
INSERT INTO `[プロジェクト名].[データセット名].demo`(date_year, date_month, date_day)
VALUES
(2021, 1, 1),
(2021, 1, 2),
(2021, 1, 3)
一時UDFの作成方法
今回は年,月,日のカラムをもとに日付を生成するUDFとしてmake_date関数を実装し、"demo"テーブルに適用していきます。 下記がそのクエリです。
-- 一時UDFを作成
CREATE TEMPORARY FUNCTION make_date(year INT64, month INT64, day INT64) AS (
DATE(year, month, day)
);
-- "sales"テーブルで適用
SELECT
*,
make_date(date_year, date_month, date_day) AS date_ymd
FROM
`[プロジェクト名].[データセット名].demo`
"CREATE TEMPORARY FUNCTION"と表記することで一時UDFを作成することができます。 make_date関数の引数には"year","month","day"を設定し、それをもとにDATE関数を用いて日付を返すといった仕組みです。
実行すると、下記結果が返ってきます。

無事日付カラムが追加されていることが確認できました。
今回はSELECT文でUDFを使用しましたが、WHERE句から呼び出すことも可能なので、
例えば
1カ月前の日付を生成するUDFを用意
→WHERE句から呼び出して1カ月前のログを抽出
なんてことも簡単にできます。
また、下記のようにUDFから別のUDFを呼び出すことも可能です。
-- 一時UDFを作成
CREATE TEMPORARY FUNCTION make_date(year INT64, month INT64, day INT64) AS (
DATE(year, month,day)
);
CREATE TEMPORARY FUNCTION make_date_yesterday(year INT64, month INT64, day INT64) AS (
DATE_SUB(
make_date(year, month, day),
INTERVAL 1 DAY
)
);
-- "sales"テーブルで適用
SELECT
*,
make_date(date_year,date_month,date_day) AS date_ymd,
make_date_yesterday(date_year,date_month,date_day) AS date_ymd_yesterday
FROM
`[プロジェクト名].[データセット名].demo`
make_date_yesterday関数ではmake_date関数を呼び出し、1日引くことで前日の日付を返しています。
実行すると、下記結果が返ってきます。

永続UDFの作成方法
一時UDFを作成する際は"CREATE TEMPORARY TABLE"と表記しましたが、 永続UDFを作成する際は"CREATE TABLE"と表記します。
試しに先ほど作成したmake_date関数を永続UDFとして保存してみます。 下記クエリを実行すると指定したデータセット内にmake_date関数が永続UDFとして生成されます。
CREATE FUNCTION [データセット名].make_date(year INT64, month INT64, day INT64) AS (
DATE(year, month,day)
)

後は以下のように[データセット名].[関数名]といった感じで記述することで永続UDFを呼び出すことが可能になります。
SELECT
*,
[データセット名].make_date(date_year, date_month, date_day) AS date_ymd
FROM
`[プロジェクト名].[データセット名].demo`
さいごに
いかがでしょうか?
UDFをうまく使うことで、スムーズかつ正確なデータ処理が可能になるかと思います。
ぜひ試してみてください。
イノベーション企業の時代
データ利活用、AI、IoTなどの先端技術の利用によりイノベーション社会へと変革しつつある現代社会。企業の在り方も、変革が進んでいる。
旧来の考え方では、企業は今期の利益が最重要な指標である。一方、イノベーション企業では将来得られる利益の期待値が重要な意味を持つ。例えば、Teslaのような破壊的イノベーションを起こす可能性を示すことができる企業は大きなポテンシャルを持っているため、市場から評価される社会が到来している。
破壊的イノベーションのタネは誰でも持っているわけではなく、ビジネスx技術x発想を揃えた人物がコアコンセプトを考え、プロトを作り、市場投入し評価を確かめ、ブラッシュアップしていく険しい道のりが待っている。
日々データを扱っているデータサイエンティストは、この機会に比較的恵まれているにも関わらず、分析に近視眼的に一生懸命になるあまり、現状の延長の発想で終わっている人が多いのも事実です。本体ならば、本質に立ち返り、破壊的なイノベーションを起こすタネをバランス良く考えておくのが、イノベーション企業での重要な過ごし方になります。
なお、全ての企業がイノベーションを起こそうとしているわけではなく、また、イノベーション企業の全部署でイノベーションを起こそうとしているわけではありません。従って、イノベーションを起こすチャレンジする機会に恵まれた環境に身を置くことは、自分の人生の選択に重要なことではないでしょうか?
イノベーションを起こすことにチャレンジしたい人、GRIで働く選択肢、アリだと思います
古幡征史