SQL Workbench/Jのおすすめ設定
SQL Workbench/J、デフォルトだと常用には厳しいかなーという感じですが、設定いじるとそこそこ使えるので紹介します。
設定
メニューの[Tools] > [Options]です。設定後、SQL Workbench/Jを再起動しないと反映されません。
General
- Insert closing brackets for【カッコや引用符を自動入力(「()''」にしてます)】
SQL Execution
Highlight Current Statement【実行中の部分を色付け】
Highlight errors【エラーの部分を色付け】
Workspace
- Auto-Save workspace【実行前に自動保存】
Data display
Show selection summary in statusbar【Altキーを押しながら数値列をマウスで選択すると、基礎統計量を表示】
Show row numbers【行番号を表示】
NULL String【NULLの表示($null$にしてます)】
Append results【実行結果を新しいタブで表示】
Show table name in header【フィールド名にテーブル名も表示】
Window title
- Editor filename【クエリータブのファイル名(Show filename onlyにしてます)】
ショートカットの設定
メニューの[Tools] > [Configure shortcuts]です。こちらも設定後、SQL Workbench/Jを再起動しないと反映されません。
SQL Workbench/J を使用してTREASURE DATA(Presto)に接続する
環境
TREASURE DATAに、SQL Workbench/Jから接続する想定です。
JDBCドライバの入手
SQL Workbench/Jは、JDBCドライバを介してDBMSに接続するため、接続先に応じたJDBCドライバを入手します。 (JDBCドライバが提供されていないDBMSには接続できません)
下記が最新版ですが、自環境では接続が遅い問題があり、
2.3. JDBC Driver — Presto 0.245 Documentation
こちらの記事を参考にバージョン0.179を使っています。
DataGrip w/Presto JDBC DriverがTreasureDataと相性悪い問題 - 半空洞男女関係
https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.179/presto-jdbc-0.179.jar
設定
起動すると「Select Connection Profile」が表示されます。(またはFile>Connect Window)
JDBCドライバの設定
左下Manage Driversからドライバ管理画面へ
左上アイコンから新規作成
Name→Presto
Library→JDBCドライバを選択→OK
Prestoへの接続
New profileの部分→好きな名称
Driver→Prestoを選択
URL→jdbc:presto://api-presto.treasuredata.co.jp:443/td-presto/********?SSL=true(実際の環境に合わせてください)
Username→(APIキー)
Password→空欄
Test でsuccessfulが表示されたら設定完了です。
SQL Workbench/J を使用してPostgreSQLに接続する
SQL Workbench/JからPostgreSQLへの接続を紹介します。
環境
Windows 10のローカル環境で動作中のPostgreSQLに、SQL Workbench/Jから接続する想定です。
- Windows 10 64bit
- SQL Workbench/J Build127
- PostgreSQL 10.15.1(デフォルト設定でインストール)
- PostgreSQL JDBC Driver 42.2.18
JDBCドライバの入手
SQL Workbench/Jは、JDBCドライバを介してDBMSに接続するため、接続先に応じたJDBCドライバを入手します。 (JDBCドライバが提供されていないDBMSには接続できません)
設定
起動すると「Select Connection Profile」が表示されます。(またはFile>Connect Window)
JDBCドライバの設定
左下Manage Drivers > PostgreSQLを選択 > Library > (JDBCドライバを選択) > OK

PostgreSQLへの接続
New profileの部分→好きな名称
Driver→PostgreSQLを選択
URL→jdbc:postgresql://localhost:5432/(実際の環境に合わせてください)
Username→(ユーザー名)
Password→(パスワード)
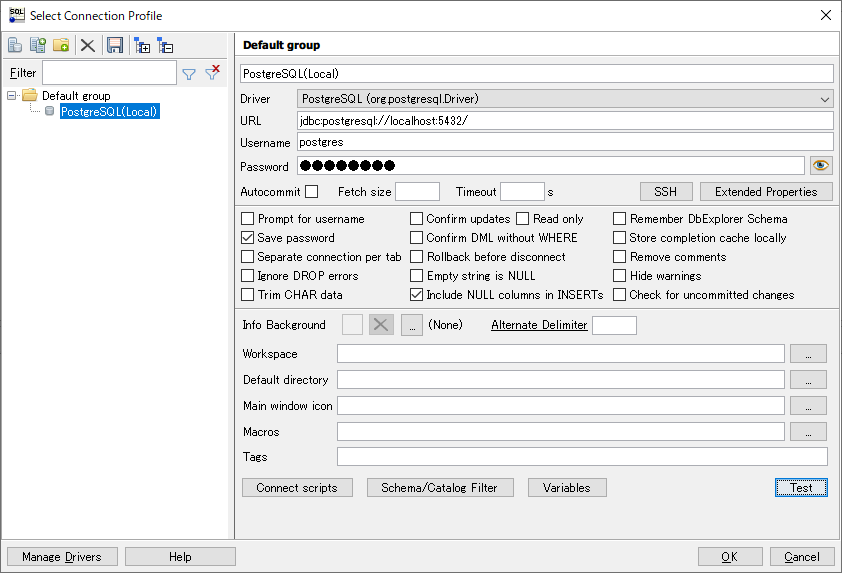
Test でsuccessfulが表示されたら設定完了です。
WOW2020チャレンジ ~AND検索とOR検索の切替(Week 29)~
WOW2020 Week 29で、AND検索とOR検索を切り替える方法が紹介されました。
2020 Week 49: Can you toggle between AND & OR filtering logic? – Workout Wednesday *1
ポイントとなる作り方を解説したいと思います。
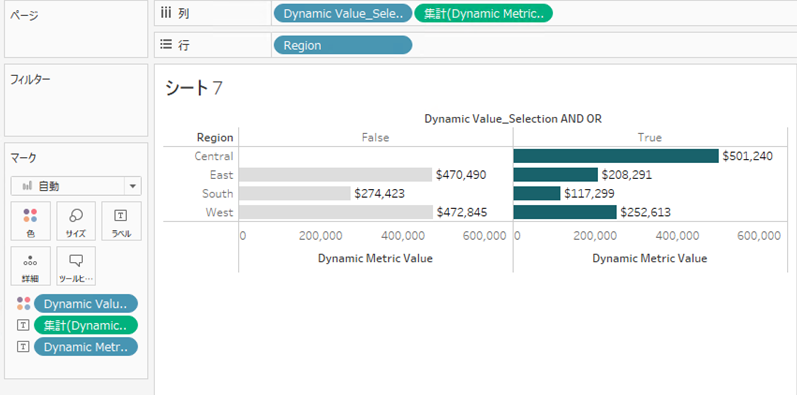
完成イメージになります。左上のフィルタでAND検索とOR検索を選択できます。
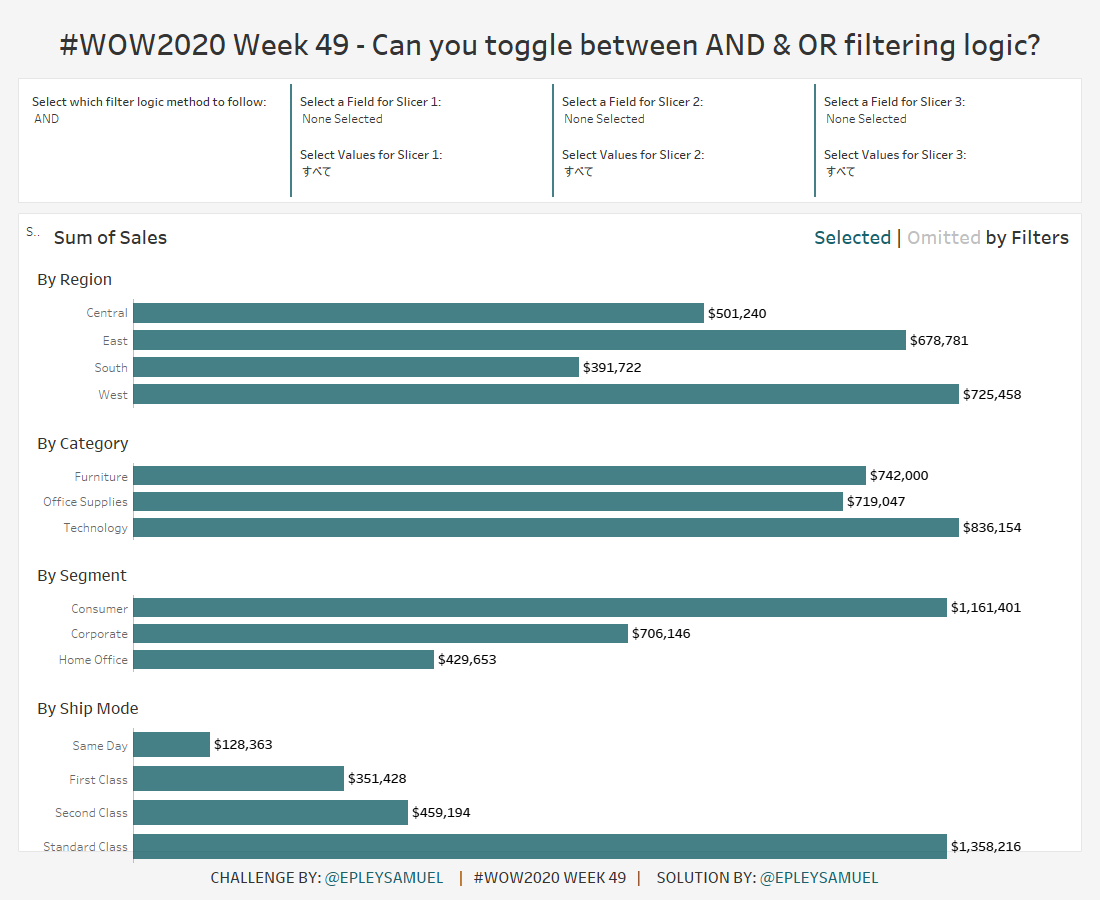
1. パラメータの作成
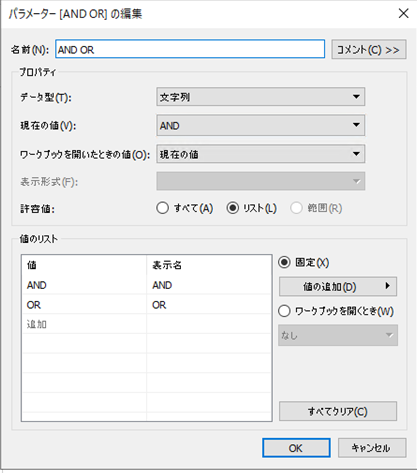
(1)AND ORの作成
AND検索とOR検索を切り替えるためのパラメータの作成になります。
データ型は文字列にします。許容値をリストにして、"AND" と "OR" を記入して下さい。
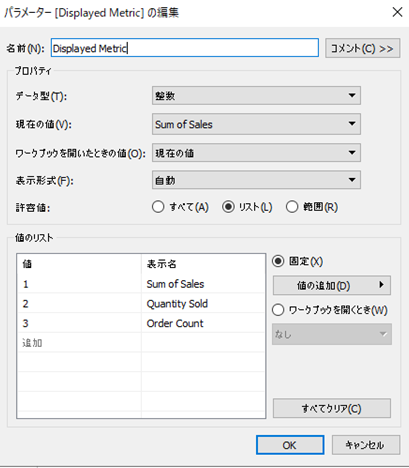
(2)Displayed Metricの作成
ダッシュボードに表示する値を選択するパラメータを作成します。完成図にも、二段目にあるチャートの上部に表示されています。
データ型を整数型にして、許容値はリストにして下さい。リストの値
1が "Sum of Sales" 、2が "Quantity Sold" 、3が "Order Count" となります。
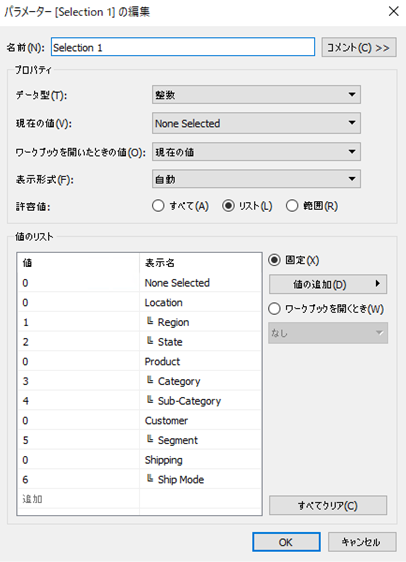
(3)Selection(Select a Field for Slicer)の作成
AND/OR検索の選択肢一覧となるパラメータを作成します。
データ型は整数型で、許容値はリストになります。値のリストは、見易さのために、階層ごとに並べています。カラムとして存在しておらず、かつ各階層の代表名となるものを0に、選択肢となるものは、それぞれ数字が付けられています。
Selection1、Selection2、Selection3と同じものを三つ作ります。
2. 計算フィールドの作成
(1)Dynamic Metric Valueの作成
1.(2)の Displayed Metric パラメータの値と使用するカラムを紐づける操作を行っています。
IF [Displayed Metric] = 1 THEN SUM([Sales])
ELSEIF [Displayed Metric] = 2 THEN SUM([Quantity])
ELSEIF [Displayed Metric] = 3 THEN COUNTD([Order ID])
ELSE NULL
END
(2)Dynamic Metric Prefixの作成
Salesを表示するときは、$が表示されるようにしています。
IF [Displayed Metric] = 1 THEN "$" ELSE "" END
(3)Dynamic Value_Selectionの作成
1.(3)の Selection(Select a Field for Slicer)パラメータの値と使用するカラムを紐づける操作を行っています。
それぞれ、Selection1、Selection2、Selection3に対して作ります。
IF [Selection 1] = 1 THEN [Region]
ELSEIF [Selection 1] = 2 THEN [State]
ELSEIF [Selection 1] = 3 THEN [Category]
ELSEIF [Selection 1] = 4 THEN [Sub-Category]
ELSEIF [Selection 1] = 5 THEN [Segment]
ELSEIF [Selection 1] = 6 THEN [Ship Mode]
ELSE "No Selection"
END
3. セットの作成
(1)Select Values for Slicerの作成
2.(3)の Dynamic Value_Selection からセットを作成します。
全般のすべて使用を選択します。名称を "Select Values for Slicer 1:" として下さい。
同様に、Select Values for Slicer 2:、Select Values for Slicer 3:も作って下さい。

4. 計算フィールドの作成
(4)Dynamic Value_Selection AND ORの作成
1.(1)の AND ORパラメータ、2.(3)の Select Values for Slicer、 3.(1)の Dynamic Value_Selectionで、AND検索とOR検索の切替ロジックを組み立てます。
IF [AND OR] = "AND" AND ([Select Values for Slicer 1:] = TRUE
AND [Select Values for Slicer 2:] = TRUE
AND [Select Values for Slicer 3:] = TRUE)
THEN TRUE
ELSEIF [Dynamic Value_Selection 1] = "No Selection"
AND [Dynamic Value_Selection 2] = "No Selection"
AND [Dynamic Value_Selection 3] = "No Selection"
THEN TRUE
ELSEIF [Dynamic Value_Selection 1] != "No Selection"
AND [Dynamic Value_Selection 2] = "No Selection"
AND [Dynamic Value_Selection 3] = "No Selection"
AND [AND OR] = "OR" AND [Select Values for Slicer 1:] = TRUE
THEN TRUE
ELSEIF [Dynamic Value_Selection 1] = "No Selection"
AND [Dynamic Value_Selection 2] != "No Selection"
AND [Dynamic Value_Selection 3] = "No Selection"
AND [AND OR] = "OR" AND [Select Values for Slicer 2:] = TRUE
THEN TRUE
ELSEIF [Dynamic Value_Selection 1] = "No Selection"
AND [Dynamic Value_Selection 2] = "No Selection"
AND [Dynamic Value_Selection 3] != "No Selection"
AND [AND OR] = "OR" AND [Select Values for Slicer 3:] = TRUE
THEN TRUE
ELSEIF [Dynamic Value_Selection 1] != "No Selection"
AND [Dynamic Value_Selection 2] != "No Selection"
AND [Dynamic Value_Selection 3] = "No Selection"
AND [AND OR] = "OR" AND ([Select Values for Slicer 1:] = TRUE
OR [Select Values for Slicer 2:] = TRUE)
THEN TRUE
ELSEIF [Dynamic Value_Selection 1] != "No Selection"
AND [Dynamic Value_Selection 2] = "No Selection"
AND [Dynamic Value_Selection 3] != "No Selection"
AND [AND OR] = "OR" AND ([Select Values for Slicer 1:] = TRUE
OR [Select Values for Slicer 3:] = TRUE)
THEN TRUE
ELSEIF [Dynamic Value_Selection 1] = "No Selection"
AND [Dynamic Value_Selection 2] != "No Selection"
AND [Dynamic Value_Selection 3] != "No Selection"
AND [AND OR] = "OR" AND ([Select Values for Slicer 2:] = TRUE
OR [Select Values for Slicer 3:] = TRUE)
THEN TRUE
ELSEIF [Dynamic Value_Selection 1] != "No Selection"
AND [Dynamic Value_Selection 2] != "No Selection"
AND [Dynamic Value_Selection 3] != "No Selection"
AND [AND OR] = "OR" AND ([Select Values for Slicer 1:] = TRUE
OR [Select Values for Slicer 2:] = TRUE
OR [Select Values for Slicer 3:] = TRUE)
THEN TRUE
ELSE FALSE
END
5. シートの作成
(1)By Regionの作成
列に[Dynamic Value_Selection AND OR]と[Dynamic Metric Value]、行に[Region]を置きます。
色に、[Dynamic Value_Selection AND OR]を置き、別名の編集からFalseをomittedに、Trueをselectedに変え、色を灰色と青緑色に変更します。
テキストに、[Dynamic Metric Value]と[Dynamic Metric Prefix]を置き、ラベルの編集から、表示されるラベルの順番は、[Dynamic Metric Prefix][Dynamic Metric Value]となるようにして下さい。(細かなレイアウトの調整については省略します。)
それぞれ Category、Segment、Ship Mode についてシートを作ります。
6. ダッシュボードの作成
タイトル、シート、パラメータを配置してダッシュボードを完成させていきます。(説明は省略します。)
以上がAND検索とOR検索を切り替える方法となります。機会があれば使ってみて下さい。
WOW2020チャレンジ ~二次元チャートの作成(Week 22)~
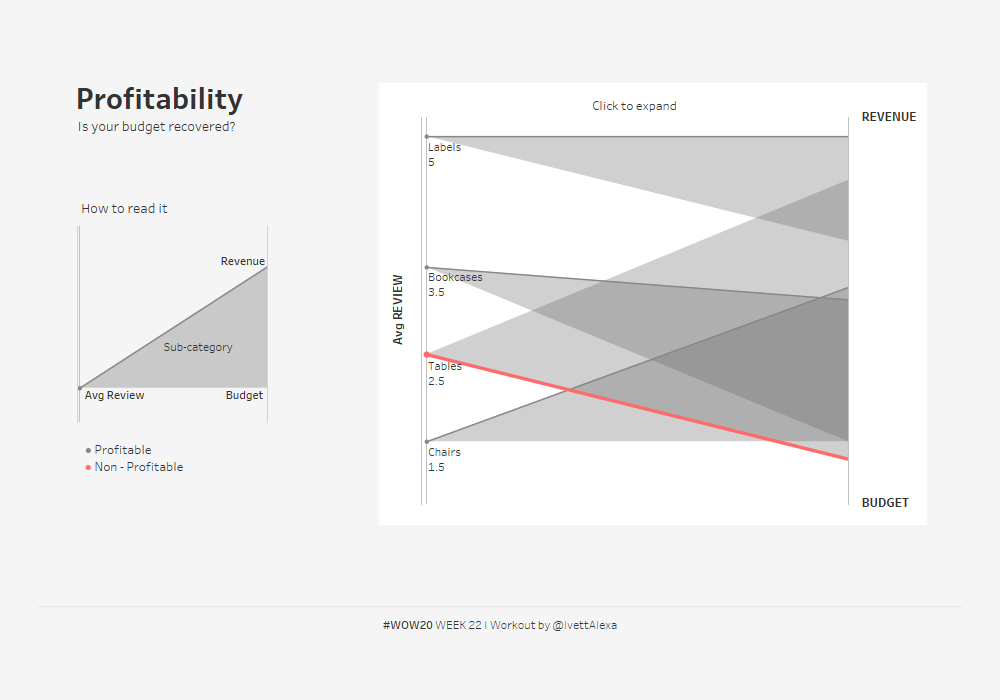
WOW2020 Week 22で、紹介されたダッシュボードを作ってみようと思います。
2020 Week 22: Profitability spotlight – is your budget recovered? – Workout Wednesday *1
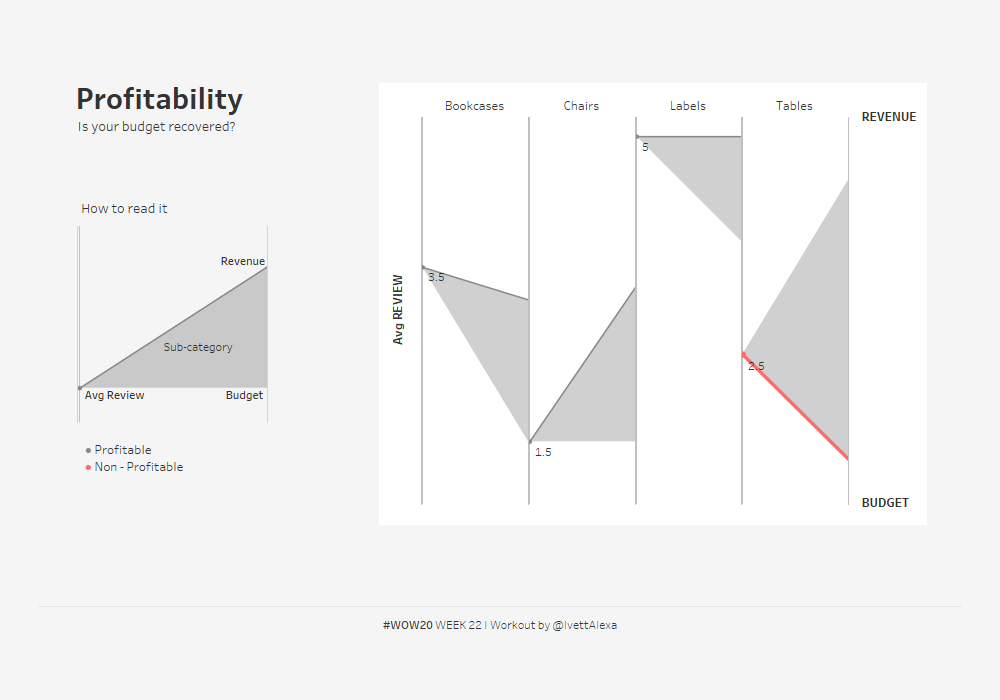
チャートの上部にあるClik to expandをクリックすると下図のように変わります。また、下図の左側にあるAvg REVIEWをクリックすると元のチャートに戻ります。
1. データーソースの作成
同じデーターソースを三つユニオンします。
2. 計算フィールドの作成
(1)path
IF [Table Name]='WW' THEN 1
ELSEIF [Table Name]='WW1' THEN 2
ELSE 3
END
(2)FIXED REVIEW
AVG( ([Review]-{ FIXED :MIN( [Review])})
/ ({FIXED :MAX( [Review])} - {FIXED:MIN( [Review])}))
(3)FIXED PROFIT and SALES
(IF ATTR([Table Name])='WW1' THEN
(AVG([Revenue])-MIN({ FIXED [Table Name]:
MIN(IF [Table Name]='WW1'
THEN ([Revenue])
END)}))
/
( (MAX({ FIXED [Table Name]:
MAX(IF [Table Name]='WW1'
THEN ([Revenue])
END)})
-
MIN({ FIXED [Table Name]:
MIN(IF [Table Name]='WW1'
THEN ([Revenue])
END)})))
ELSE (AVG([Budget])-MIN({ FIXED [Table Name]:
MIN(IF [Table Name]='WW2'
THEN ([Budget])
END)}))
/
( (MAX({ FIXED [Table Name]:
MAX(IF [Table Name]='WW2'
THEN ([Budget])
END)})
-
MIN({ FIXED [Table Name]:
MIN(IF [Table Name]='WW2'
THEN ([Budget])
END)})))
END)
(4) X
FLOAT(If [Path]=1 THEN 0
ELSEIF [Path]=2 OR [Path]=3 THEN 1
END)
(5)Y
IF ATTR([Path])=1 THEN [FIXED REVIEW]
ELSEIF ATTR([Path])=2 THEN [FIXED PROFIT and SALES]
ELSEIF ATTR([Path])=3 THEN [FIXED PROFIT and SALES]
END
(6)Color for - Profit
収益が予算を下回ったとき、赤く表示するための計算フィールドです。
3. シートの作成
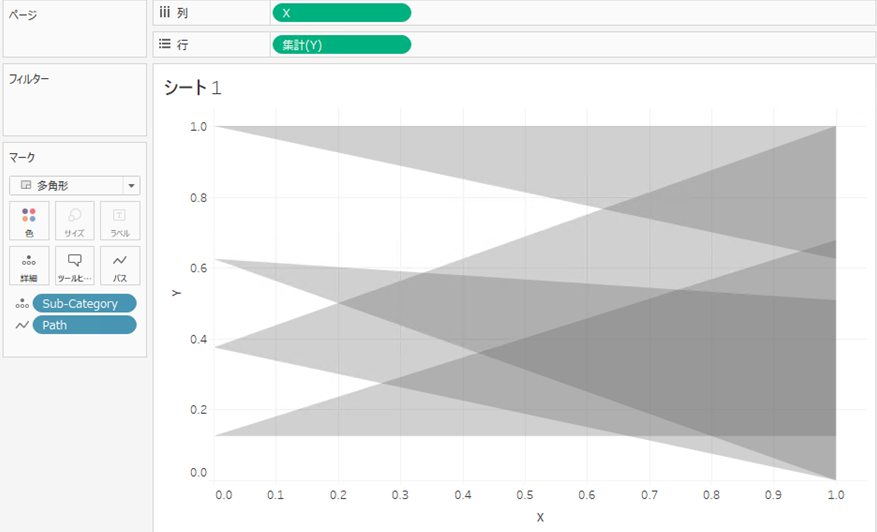
(1)多角形フラグの作成
列に、ディメンションに変換したXを、行にYを置きます。
マークを多角形に変え、Pathをパスに、詳細にSub-Categoryを配置します。
色も灰色に、不透明度30%に変更します。
(2)線フラグの作成
行にあるYを複製し、マークを線に変更し、二重軸とします。色の効果 マーカーはすべてを選択します。
X軸の範囲を、固定にし、-0,01から0.8にします。これは、見栄えをよくするための操作になります。
Y軸は、目盛りを無くし、名称を "Avg REVIEW" にします。
色に、2.(6)のColor for - Profit を置き、不透明度100%にします。

4. セットアクションの設定
(1)セット Sub-Category Set の作成
Sub-Categoryからセットを作成します。全般のリストから選択を選んで下さい。
(2)計算フィールド Expand の作成
IF [Sub-Category Set Point]='t'
THEN [Sub-Category]
ELSE 'Click to expand '
END
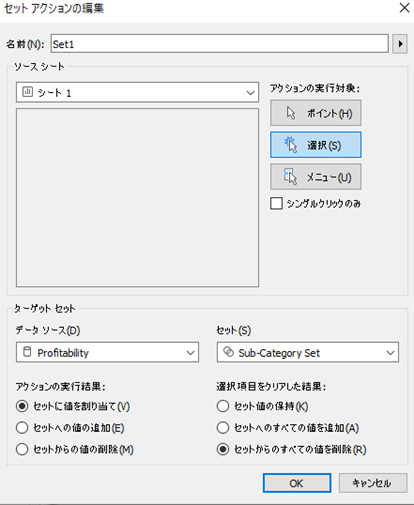
(3)セットアクションの編集
ワークシート→アクション→アクションの追加→セット値の変更 からセットアクションの編集を行います。
下図のように設定して下さい。(データーソースは1.で作成したものを選択します。)
5. 平均収益のラベルの設定
(1)計算フィールド Label for Sub_Category/Score の作成
{INCLUDE [Sub-Category]: IF MAX([Sub-Category Set Point])='t'
THEN STR( (AVG([Review])))
ELSE MAX([Sub-Category])
END }
この計算フィールドを棒グラフのラベルに置きます。
(2)計算フィールド Label for Sub_Category の作成
{INCLUDE [Sub-Category]: IF MAX([Sub-Category Set Point])<>'t'
THEN STR(AVG([Review]))
ELSE ''
END }
この計算フィールドを棒グラフのラベルに置きます。
以上が説明となります。直感的に収益と予算の関係がわかるチャートなので、是非作ってみて下さい。
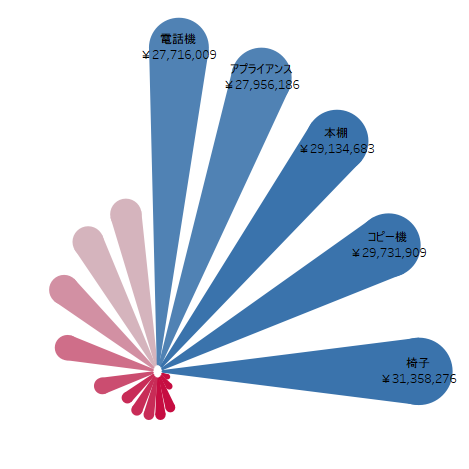
TableauでPetal Chartsをつくってみた
今回は、Petal Chartsをつくります。
Petalとは花弁という意味です。花弁の大きさで数値の大小関係を直感的に理解することができるチャートとなります。
下図を作っていきます。このチャートは、サンプル スーパーストアのサブカテゴリごとの売上を表示しています。
<作り方>
1. データーソースの作成
同じデーターソースを二つユニオンします。

2. 計算フィールドの作成
(1)Path
IIF([表名]="注文", 0, 1)
(2)Score
[売上]*[Path]
(3)Size
[売上]*[Path]
(4)Radial Angle
(INDEX()-1)*(1/WINDOW_COUNT(COUNT([Score])))*2*PI()
(5)Radial Inner
0.2
(6)Radial Outer
1
(7)Radial Normalised Lenght
[Radial Inner]+IIF(ATTR([Path])=0, 0, SUM([Score]) /
WINDOW_MAX(SUM([Score]))*([Radial Outer])-[Radial Inner])
(8)Radial X
[Radial Normalised Lenght]*COS([Radial Angle])
(9)Radial Y
[Radial Normalised Lenght]*SIN([Radial Angle])
3. チャートの作成
(1)計算フィールドの配置
列にRadical Xを、行にRadical Yを配置します。
マークを線に変更し、Sizeをサイズに、詳細にサブカテゴリ、ディメンションに変換し不連続にしたPathを置きます。
 (2)表計算の編集
(2)表計算の編集
列にあるRadical Xと、行にあるRadical Yを右クリックし、それぞれ表計算の編集を行います。
Radial Normalised Lenght と Radial Angle に対して、特定のディメンションにサブカテゴリを選択して下さい。サブカテゴリはPathより上の位置に移動させて下さい。


表計算の編集を行うと下図のようになります。

(3)レイアウトの調整
サブカテゴの並び替えは、詳細にあるサブカテゴリを右クリックして、並び替えを選択します。並び替えは、フィールドを選択し、売上の降順になるように設定します。
サイズの調整、色に売上を置き、テキストにサブカテゴや売上を配置します。あとは、ヘッダーや軸のタイトル、グリット線を消すなどして、好みに調整すれば終わりとなります。
以上が作り方の説明となります。
エレベーターの運行最適化に機械学習が必要?シミュレーションで体感
まずエレベータの運用ルールを振り返る
最近、機械学習の技術の発展を受けて、エレベーターを効率的に運行させるためにも機械学習を応用する試みがなされています。これを聞くと、「エレベーターの運行って、機械学習を使わなくてはならないほど複雑ではないのでは?」と思う方もいるかもしれません。
この記事は、「混雑緩和」のためにエレベータを増設しても「エレベータがなかなか来ない」という現象をシミュレーションで再現しながら議論していきます。
エレベーターの運行は、日ごろの経験からもわかるように、以下の簡単なルールで表すことができます。
誰も待っていなければ動かない
誰かが待っていると、その階に向かって移動する
エレベーター内の行先ボタンに従って移動する
移動中に、同じ方向に向かいたい人が待っていたら、ついでに乗せる
エレベーターの進行方向と逆の方向で待っている人は一旦無視する
上記のシンプルな仕組みであれば、機械学習を使わなくても、「ルールベース手法」で十分なわけです。
機械学習とルールベース手法の違いについては、こちらをご参照ください;
【超優しいデータサイエンス・シリーズ】人工知能と機械学習の関係 - GRI Blog
では、なぜ機械学習を用いた運行最適化が注目されているのでしょうか?
それは、利用者数が多く、それに対処するために複数のエレベーターを併設している場合に起こる、ある厄介な現象に原因があります。その現象とは、「複数あるエレベーターが、お互いに競うように近い階にあって、どれもなかなか来ない」というものです。
エレベータの最適化を数学的に理解
上記の現象を、数学的なイメージで簡単に説明することができます。
ここでは、エレベーターの数は2個と仮定しましょう。
最初は、2つのエレベーターは、離れた階に位置しています
一方のエレベーター(A)が、もう一方のエレベーター(B)よりも、確率的な現象として、やや多めの客を対応することになったとします
Aは対応に時間を要し、先に進むのが遅れます。その分、Aが対応しなくてはならない(Aの先で待っている)客の数は増えていきます。
Aの進行が遅れることで、BはAに接近していきます。これにより、Bが対応しなくてはならない客の数は、Aが対応した後の短い時間内に発生した分のみなので、Aよりも少なくなます。これにより、Bは早く先に進むことができ、Aにますます接近します。
BがAを追い越してしまうと、この関係が逆転し、AがBに接近しやすくなります。
このように、2台のエレベーターはお互いに競い合ったように近い階に位置しやすくなります。
エレベータの挙動をシミュレーションで検証
今回は、この現象を、乱数を使ったシミュレーションにより検証してみました。シミュレーションにはnumPyパッケージを使用しました。
ルールベースで運用するエレベーターを再現すべく、以下のようなシミュレーションを組みました。
シナリオ1:エレベーターが1台の時の混雑状況
まずは、エレベーター1機の場合で、建物は1~9階の9階建てという設定にしました。
単位時間(例えば1秒)あたり、約1/4の確率で新たな待機者が現れます。(厳密には、4/15の確率となっています。アルゴリズムを組む手間の都合上で、深い意味はありません)
待機者の出発階と目的階は乱数で1~9の範囲で出力します(出発階≠目的階とする)。
エレベーターの昇降速度は、単位時間当たり1階分、開閉時間は、昇降人数によらず5単位時間とする。
エレベーターの乗客定員はないものとする(やや無理のある設定なので、今後アルゴリズム改善の余地あり)
エレベーターは以下のアルゴリズムに従って運行するとします。
(1) 機内に乗客がおらず、かつ誰も待っていなければ動かない
(2) 機内に乗客がおらず、誰かが待っていると、その階に向かって移動する
ここでは、現在地に対して、逆方向に複数人が待機している場合は、直前の移動方向を優先
また、目的階が逆方向となる複数の客が同一階に待機している場合も、直前の移動方向と一致する客を優先
(3) 機内に乗客がいる場合は、その乗客の目的階に向かって移動する
(4) 移動中に、同じ方向に向かう人が待っていたら、ついでに停止し扉が開いて乗せる
(5) 移動中に、逆の方向に向かう人が待っていても、無視して通過する
5000単位時間までの、シミュレーション結果は以下の通りとなります。1~9階を常に往復し続けています。
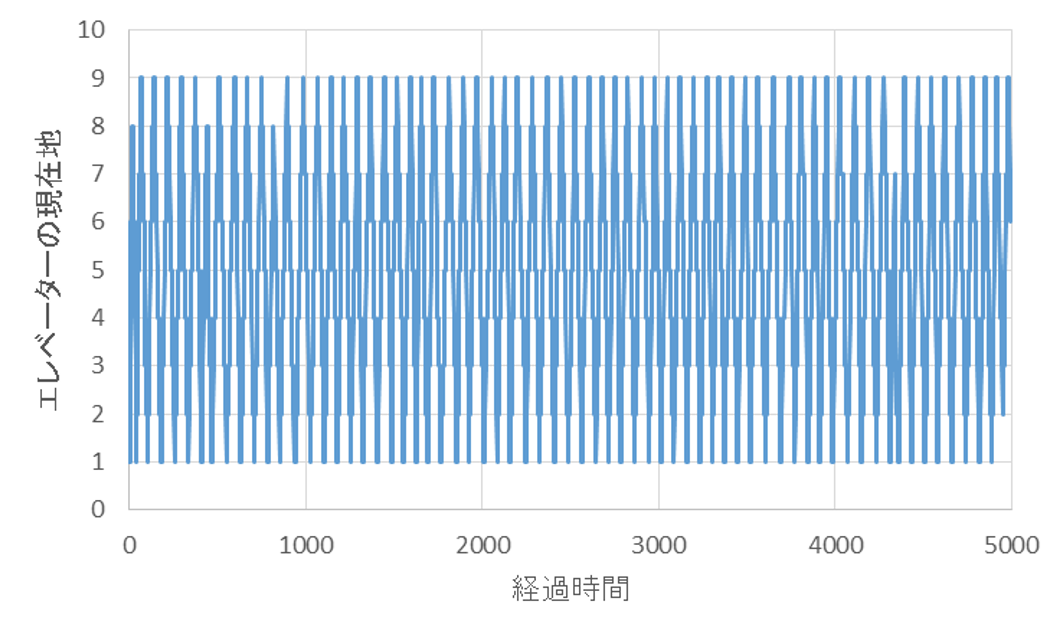
300単位時間までを拡大すると、下記のようになります。
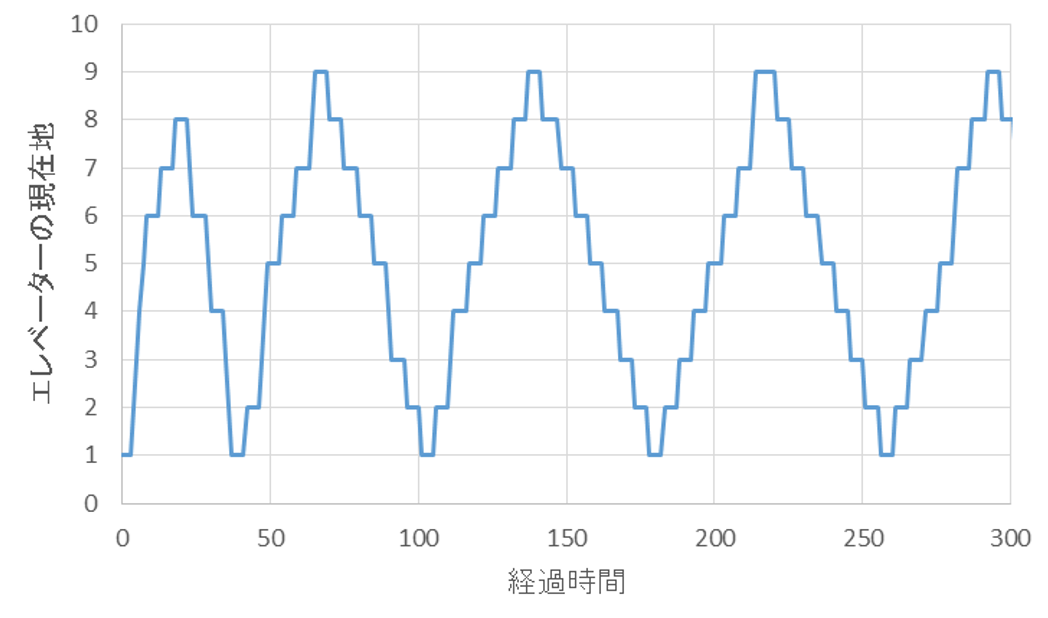
上記の図から、ほぼ各階で止まっていることが確認できます。すなわち、各階で、待機している人、もしくは、降りる人が存在している状況です。相当混雑している様子が伺えます。
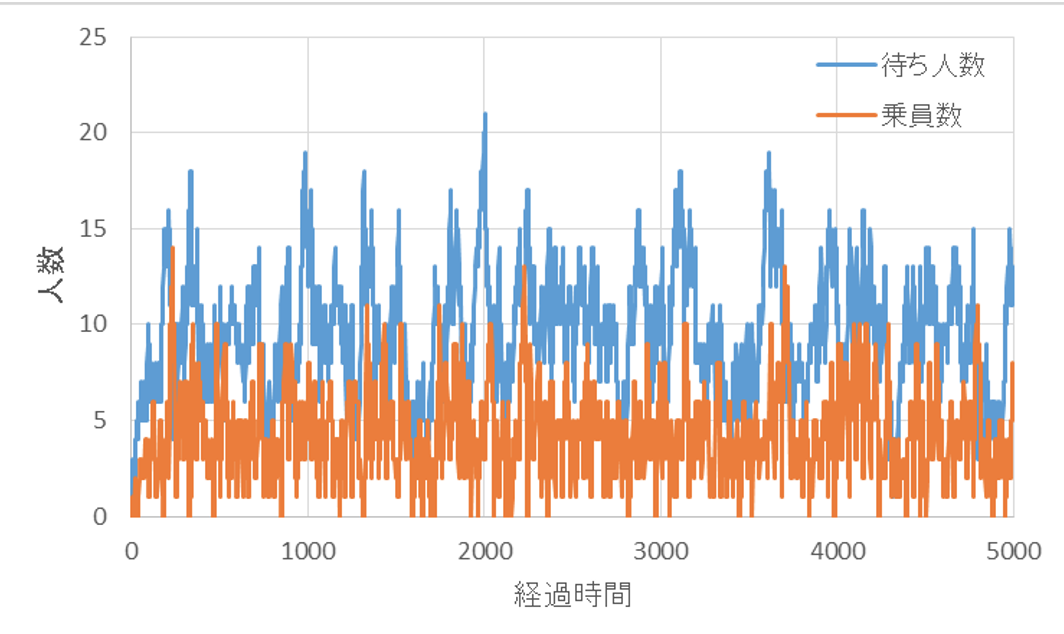
実際に、待っている人数と、エレベーター内の乗員数をプロットすると、下図のようになります。平均9.4人、最大21人が待機していて、エレベーター内には平均4.3人、最大14人が乗っている状況です。これでは快適なエレベーター環境とは言えませんね。

シナリオ2:エレベーター増設すると混雑が緩和される?新たな問題点は?
シナリオ1で作成したアルゴリズムを拡張し、エレベーターを2台に拡張しました。その際、以下のルールを追加しました。
- 2機とも乗客がおらずフリーの時は、1号機が優先し、2号機は動かない。
5000単位時間までの、シミュレーションの結果は以下の通りです。
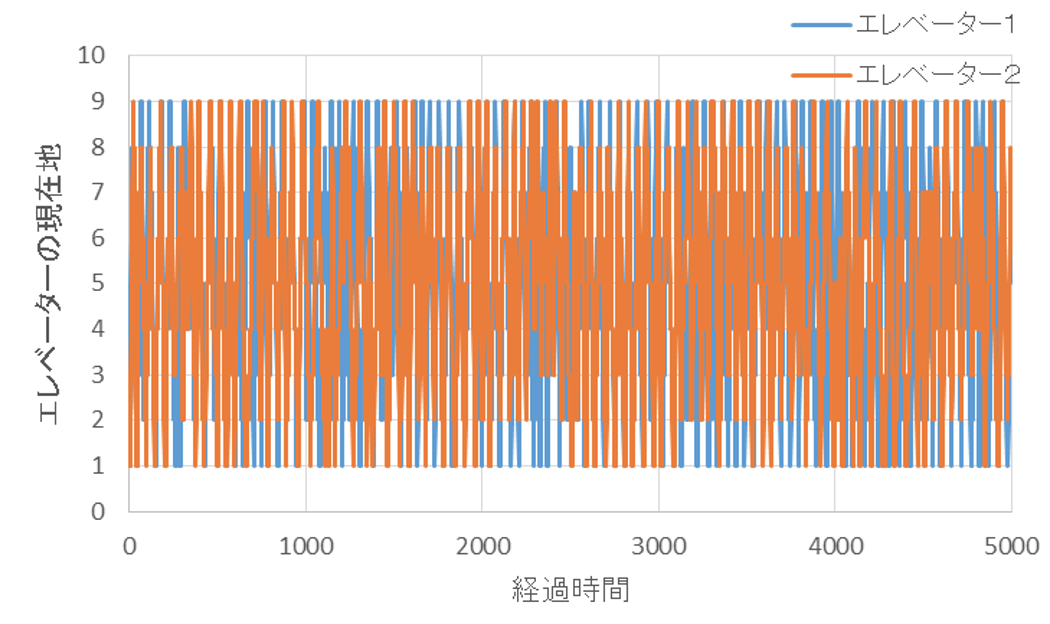
1~9階を常に往復し続けているようですが、この図だけではわかりにくいので、300単位時間までを拡大しました。確かに、最初は1号機から動き出し、2号機はその後に待ち始めた人を対応し始めるのですが、すぐに1号機に追いつき、1号機と2号機はほぼ同調して動いてしまいました。
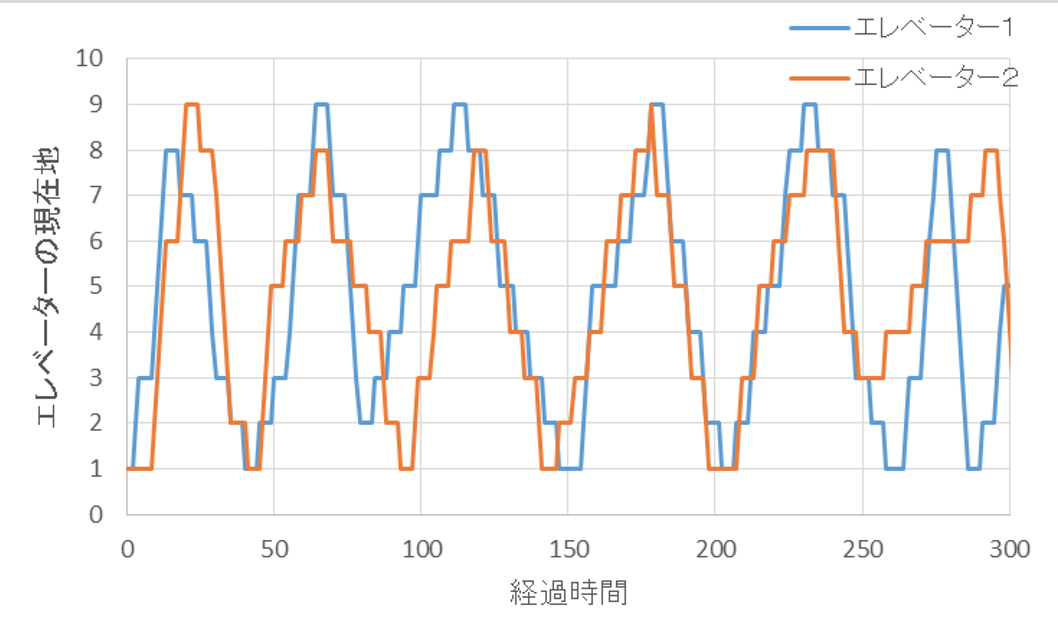
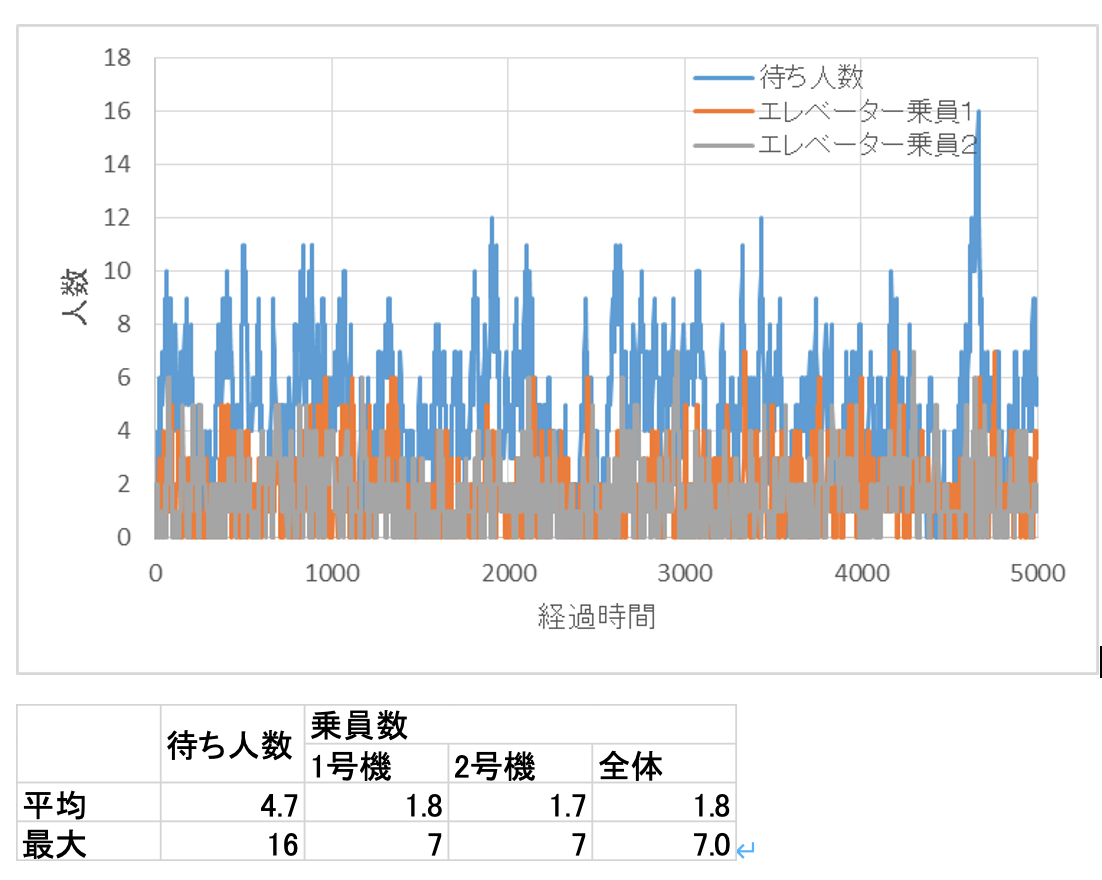
エレベーターの増設の目的は混雑と待ち人数の緩和でしたから、その効果を見てみましょう。
確かに、待機している人の平均は4.7人に減り、エレベーター内の乗員も平均1.8人、最大7人と、混雑が大幅に改善され、混雑緩和という目的は達成しているといえます。
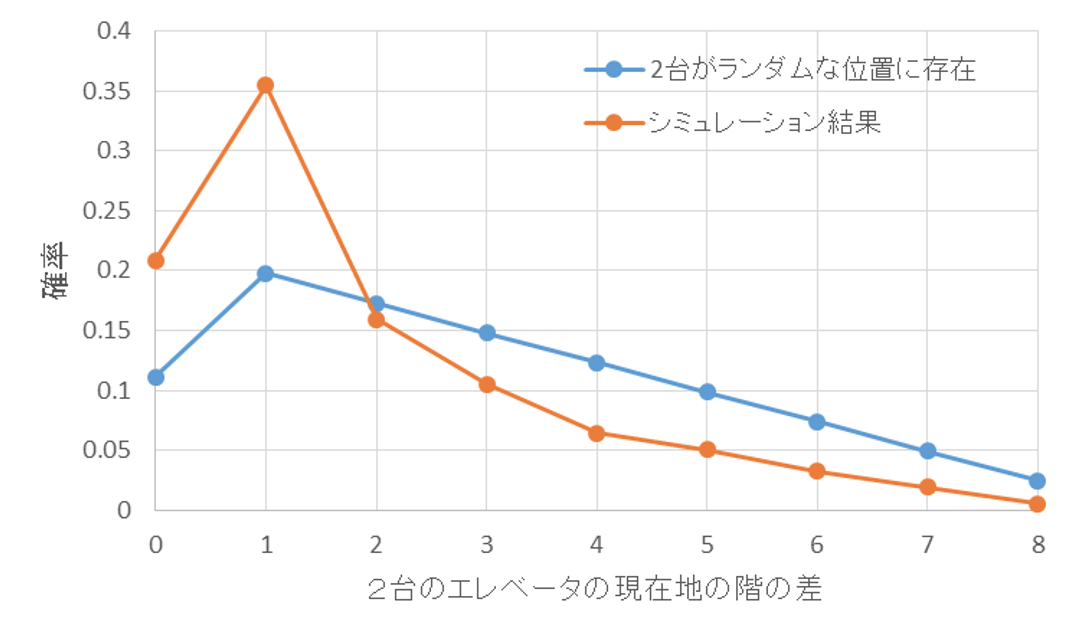
しかしながら、2台のエレベーターが近いところにあって、「なかなか来ない」問題は残っています。実際、この2台のエレベーターはお互いどれくらい近い位置に存在しているのでしょうか?
ここで2台のエレベーターが、それぞれ1~9階のいずれかにランダムな確率で存在するとします。その場合、2台のエレベーターの現在地の差は0~8のいずれかとなり、その確率は下図のようになります。期待値を計算すると、2.96となります。ところが、エレベーターの動作アルゴリズムに従ってシミュレーションを行うと、下図のように、現在地との差が0~1のいずれかである確率がランダムな場合よりも高くなり、期待値は1.87となりました。すなわち、エレベーターを増設すると、2台のエレベーターは近い位置で競い合ってしまう現象が再現できました。
まとめ
今回、簡単なシミュレーションにより、複数のエレベーターが互いに追いかけあう現象を観察してみました。
問題を簡単にするため、以下のような仮定を置き、必ずしも現実を再現できていない部分もあります。
乗員定員を定めない→現実には定員オーバーすると乗れない
開閉時間は、昇降人数によらず5単位時間→現実には昇降する人が多くなると開閉時間が長くなる
出発階と目的階をランダムに等確率で発生させている →現実には、出発階と目的階は1階(または出口のある階)に集中する
しかしながら、冒頭で述べたような「ルールベース」の運用法で発生してしまう「エレベーター同士の追いかけ合い」の本質を再現することには成功したと考えています。この現象は、「待たされている」「なかなか来ない」という不満感をもたらしてしまいます。この不満感を、混雑緩和という重要な目的を損なうことなく、いかに解決するか。その実現のため、機械学習の手法が用いられ、研究されていることを実感できます。
担当者:ヤン・ジャクリン(分析官・講師)