Tableauの曜日の仕様メモ
Tableauの曜日について気になることを調べたことのメモです。
曜日の出し方
①書式設定(カスタム)で出す
書式設定でDDD、DDDDと書くと曜日表示できます。

②カスタム日付フィールドを作成する
日付フィールドの”作成”から”カスタム日付の作成”を選択すると曜日が選べます。
曜日を選んでOKを押すと曜日が格納されたフィールドができます。

曜日がふたつある~(ちいかわ)
ISOの曜日と普通の曜日の違いって何でしょうか。
ISOとグレゴリオ暦がある
ISOとは国際規格で決められた暦のようです。
https://ja.wikipedia.org/wiki/ISO_8601
一方、Tableauでの標準の日付はグレゴリオ暦を採用しているようです。
https://help.tableau.com/current/pro/desktop/ja-jp/date_properties.htm
違いとしてはISOは月曜始まり、グレゴリオ暦は日曜始まりという点です。
曜日を返してくれる関数に、DATEPARTとISOWEEKがあります。
DATEPART("weekday",[Date])は日曜を1、土曜を7とした整数で返してくれます。
ISOWEEKDAY([Date])はISOだから月曜を1、日曜を7とした整数で返してくれます。
曜日単位の日付を計算する時に使えます。
ちなみに1-7の整数→曜日の変換も可能。
Tableauの表示はこんな感じ。

このあたりの違いは、曜日単位の日付の計算とかする時に気を付けたほうがいい気がする。
そのISOISOWEEKDAY、必要ですか。
1-7以外の数字を曜日変換できるのか
1-7は曜日変換できるんですが、それ以外でも曜日変換はできるのでしょうか。
-10~10のデータを用意

書式設定をDDDDにすると曜日になった。
7以外でも書式設定では変換できるみたいです。
データ数値/7の余りでも見ているのでしょうか。

おわり
【体験記】データサイエンス数学ストラテジスト資格検定
皆さんは、データサイエンス数学ストラテジスト資格検定をご存知でしょうか。公益財団法人 日本数学検定協会から9/21に公開されました。今までにない数学の検定であり、データサイエンスの基盤となる数学スキル、リテラシーを学び、その理解度・習熟度を測定することで、データサイエンスにおける数学を扱う技能を認定する資格です。大きく分けて4つの分野が出題されています。


レベルには[中級]と[上級]があります。資格試験の詳細は運営とe-learningを担当しているアガルートアカデミーのHPにわかりやすく記述されていますので、ご参照ください。対策講座もあります。
試験好き(笑)な私自身も、この革新的な資格試験にかなり興奮し、暇の連休にこんなものも書きました。
さて、今回は、データサイエンス数学ストラテジストの試験を公開日当日に受験した方(Aさん)の体験記を共有します。実は、このAさんは、データサイエンスをGRIの講座で学び始めました。データサイエンスを勉強してきた経緯、何が得られたのか、それが現在のキャリアに役に立っているのか、というストーリーも語られています。これからデータサイエンスを学ばれる方に少しでも参考になれればと思います。
それでは、Aさんの受験体験記を修正なしで、以下引用いたします。
2021年9月21日にスタートしたデータサイエンス数学ストラテジスト検定の中級を、受付開始当日に受験しました。受験の動機、準備、試験の感想の順で、報告します。
●受験の動機
国内のメーカーにて研究・開発業務に従事している36歳です。国立の理工系大学院を修了しましたが、データサイエンスが専門分野ではないため、数学や情報科学の知識は、大学1~2年のレベルです。
日頃の業務でも、Excelを用いたデータ分析や、回帰分析などの基礎的な統計分析の経験はあっても、pythonや機械学習などのデータサイエンスの知識は、1~2年前まではほとんどない状態でした。
昨今のデータサイエンス人材育成の流れの中、私の従事する会社でも、機械学習やインフォマティクスの活用が推進されて、人材育成が進んでいます。また、同業の他社でも、同じように(あるいはそれ以上に)データサイエンスが注目されていることを肌で感じています。
私自身は、会社の中では直接データサイエンスのプロジェクトに関わっているわけではありません。しかし、これらの社会の潮流を感じる中で、スキルアップとしてデータサイエンスの知識&技術を身に着けることが重要と思い、2年前よりGRIさんの講座にお世話になっています。実務経験といえるほどではありませんが、pythonも少しずつ使えるようになり、業務の中で、今まで時間をかけてやってきた仕事の効率化や自動化を、自分なりに試しているという状況です。
データサイエンスの資格としてはG検定の合格経験があります。しかし、G検定では数学の問題は数問だけであり、主に知識問題が中心となります。今後、データサイエンス人材として活躍できるようスキルアップをしようとしたとき、どのように数学やプログラミングの勉強をしていくべきか、と考えていました。
データサイエンスで用いられる数学の領域は、偏りがあります。よく使うものと、ほとんど使わないものがあります。高校や大学の数学の教科書を一通り勉強する、ということも考えましたが、ビジネスに生かせる数学力を身に着ける目的を考えると、それはやや遠回りなのではないか、やや効率が悪いのではないか、と思っていました。
そんな時に、日本数学検定協会から「データサイエンス数学ストラテジスト」検定が始まるというニュース記事を読み、まずこれに挑戦してみようと思いました。経歴上、大学1~2年までの数学は一度勉強したことがありますので、上級合格を目指すことにしました。
・・が、上級の公式問題集を見てびっくり。結構忘れていて解けないのです。Web上での数学の試験というシステムにも慣れない中、いきなり上級にチャレンジしても、時間切れになって不合格になるのがオチではないか。それならば、まず中級を受験して、このような受験システムに慣れて、イメージトレーニングを使用ではないか、と思い、申し込み受付当日の中級受験を決断しました。
●これまでの勉強
GRIヤン講師のデータサイエンス基礎講座
アガルートのG検定対策講座→2020年11月に合格。新シラバスが始まった2021年7月にも復習として再受験し、再度合格。
今回は、ストラテジスト検定の公式問題集を中級と上級を一通り勉強。
●試験の感想
試験開始当日ということで、試験の雰囲気やシステムについての事前の情報がなく、少し時間に余裕をもって受験の申し込みを行いました。私は以前、アガルートのG検定対策講座を受講した経験があるため、アガルートのアカウントを持っており、受験の申し込みは一瞬で終わりました。アカウントがなければ、住所等の入力等がひつようとなるため、もう少し時間がかかると思います。受験の申し込みを行い、クレジット決済が完了すると、すぐに受験を開始できます。もちろん、日を改めて時間のある時に受験することもできました。
一旦試験を開始すると、途中で中断したり、やり直したりすることはできません。試験はwebブラウザ上で行いますので、事前にインターネットの通信環境に問題がないかどうか(例えば、自宅以外のイレギュラーな場所であれば、wi-fiや無線LANなどが安定しているか)をチェックし、PCの動作に不安定な点(充電は十分か?コンセントはあるか?裏で重たいプロセスが走っていないか?)がないかを確認することが重要です。お手洗いも済ませておきましょう。
準備が整ったと判断したら、自分のタイミングで「試験開始」ボタンをクリックすることで、試験を開始することができます。試験時間は90分で、経過時間と残り時間が画面上部に表示されていますので、時間を見ながら進めることができます。問題は30問で、基本的には問1から順に解いていきますが、難しかったり自信がなかったり、後回しにすることも可能です。ブックマーク機能もあり、制限時間の範囲内で何度でも戻ることができます。
公式サイトの案内や公式問題集によると、試験は「AI・データサイエンスを支える計算能力と数学的理論の理解」「機械学習・深層学習の数学的理論の理解」「アルゴリズム・プログラミングに必要な数学リテラシー」「ビジネスにおいて数学技能を活用する能力」の4つのジャンルがそれぞれ、3:1:1:1の割合で出題されると書かれています。実際の試験では、前半の半分くらいの問題は、学校の数学で習うような計算問題、方程式、関数の問題が多く、中盤にデータサイエンスの知識が求められる問題、終盤に具体的な事例に基づく応用問題があり、だいたい公式情報のジャンル順になっているように感じました。しかし、他の受験者も同じ問題順かはわかりませんし、4つのジャンルは独立ではなく、重複する部分も多いため、「この問題はどのジャンルに対応するのか」と考えるのは、あまり意味がないように感じました。
基本的な数学の問題としては、四則演算や方程式が5問程度、割合・比例・一次関数・二次関数などの関数に関する問題が5問程度で、これらの中には中学生の知識で解けるものが結構ありました。しかし、他には、三角関数や行列など高校の知識が必要なものも数問ありました。規則性を見つける問題は、このような問題に慣れておくことが、早く解くカギだと思いました。
統計学の知識として、平均値、中央値、標準偏差、回帰直線、相関などを知っておく必要がありました。また、機械学習の前処理技術として用いられる、正規化や標準化についても出題されました。これらは、すべてを手計算で求めようとすると計算ミスの原因になるので、Excelなどの表計算ソフトを別途立ち上げて置き、随時活用できるようにしておくことがおすすめです。また、関数を使いこなして、平均などの値を瞬時に計算できるようにしておくと、早く解けると思います。
機械学習の知識として、ROC曲線、畳み込み演算、サポートベクトルマシンの分離境界線、ユークリッド距離に関する出題がありました。定義式や用語の意味は問題文に書かれているため、知らなくても回答は可能だと思いますが、理解するのに時間を要してしまうので、事前に知識を持っておくことが確実に得点するためには重要でしょう。
ジャンル④の「ビジネスにおいて数学技能を活用する能力」でしょうか、最後に、比較的具体的なシーンを想定した応用問題が連続して出題されました。中学~高校までの知識で解ける内容ということで、割合や比率に関する応用問題がほとんどでした。小学校の算数で習った「速さ、時間、距離」のいわゆる「ハジキ式」のような考え方をいかに柔軟に応用できるかが、試されていました。
試験時間は90分間でしたが、個人的な事情により別のスケジュールがあったため、30分間で一通り説いた後、見直しをせずに「試験終了」ボタンを押して、退室しました。
解けなかった問題はなかったので、それなりに自信を持っていたつもりでしたが、なんと5問も間違えていました。間違いの原因を分析したところ、下記の3点があげられました。受験する方は、お気を付けください。
問題文のデータをExcelに転記するときの入力ミス
単純な計算ミス・・・まさかの13+9=20、3(a+3)2=3a2+6a+9
日頃、計算をExcelに任せてしまっているツケでしょうか、単純な計算ミスが多発しました
焦りによる問題の勘違い・・・「~%になった」と「~%増えた」は違いますよね、、、読み違えました。
また、web試験ということで、問題が画面上に表示され、計算は手元の紙で行う、というパターンは、慣れていないとなかなか集中できないものでした。私のように、本&紙で勉強した世代にとっては、目や手先が、画面から紙へ、その後マウスでクリック・・・とあちらこちらに移動しなければならず、ちょっと大変。若い世代なら難なくこなせるのでしょうか。
●試験を終えて
この度、数学ストラテジスト検定の上級合格を目指す1stステップとして、試験形式になれる目的もかねて、中級を受験しました。解けない問題はなく、制限時間にも余裕をもって解き終えることができました。しかし、久々の手計算による計算ミスなど、課題が見つかりました。
今後は、上級の合格に向けた数学の勉強を進め、今回のようなミスがないように、また、ちょっとミスをしたとしても合格できるような実力を身に着けていきたいと思います。
記事担当:ヤン ジャクリン(分析官・講師)
GoogleColab 上でファイルを操作コツ(Part2)
本シリーズGoogleColab 上でファイルを操作コツのPart1では、ColabからGoogleドライブへのアクセス法、ファイルの新規作成、アップロード、ダウンロードなどの基本的なやりとりをお伝えしました。
このPart2では、その続きとして、ドライブ上に置かれている表形式データや画像データをGoogleColabのコードに読み込む演習をしましょう。
GoogleColabから見た、ドライブ上のファイルディレクトリー
基本的に Jupyter Notebook では、Linuxコマンドを冒頭に「!」をつけることで使用することができます。

ディレクトリ構造を確認するために、「!pwd」で「今自分がどこにいるか」を確認できます。今はホーム直下の /content にいます。
次に、「!ls」でこの「content」というフォルダにはどういうもの(ファイルやサブフォルダ)が入っているかを見ることができます。その結果として、「drive」と「sample_data」というサブフォルダがあることが見えますね。
実は最近できた機能で、画面左にあるパネルのフォルダーマークから、ファイル名やディレクトリー構造が見えるようになりました。これを利用すると、嬉しいことは:
ドライブ上のファイル構造を、コードを書きながら可視化できる
ドライブ上のパスを楽にコピーできて、楽になる

データの中身も見やすくなります。例えば、ここでsample_dataフォルダをワンクリックで開いて、california_housing_train.csv をダブルクリックすると、画面の右側にデータそのものを綺麗に閲覧することができますね。このデータにはどういう列があって、それぞれの列にはどんな数値が入っているのかなど、これからこのコードで行おうとしている分析のためになる情報が見つかるかもしれません。

表形式データを読み込む
先ほどの「california_housing_train.csv」は表形式のデータです。それをpandasのDataFrameに格納し見てみましょう。

この時、pd_read() の中に記述するファイルパスは下図のように、左パネルで見えているデータ名を右クリックして、プールダウンから「パスをコピー」をし、次にコードの中の該当場所にペーストし、これで楽にデータパスを反映できますね。

画像データを読み込む
今度は、'/content/drive/' の中の My Drive にある子猫三匹が写っているサンプル画像データを読み込んでみます。画像データの処理によく使うcv2モジュールをimportします。

一般的にAnacondaなどの環境でcv2を使用する場合は、画像を表示する際によくcv.imshow() が使われます。しかし、cv.imshow() はcolabで使えないです。代わりにColab側がサポートパッチを提供しています。それが cv2_imshow(image) です。 ここで、image は cv2.imread() で画像ファイルパスを介してコード内に読み込んだデータです。
最後に、image はNumpyの配列として保持されているので、コードで単に image と打てば、配列の数値を見ることができます。

後続の記事では、Part1とPart2で学んだテクニックを生かして、GooglePhotoの画像へのアクセスや動画ファイルの自動的なダウンロードなど、発展的な「演習」をしていけたらと思います。
ここまで読んでいただきありがとうございます。また次回お会いしましょう。
担当者:ヤン ジャクリン (分析官・講師)
GoogleColab 上でファイルを操作コツ(Part1)
Google Colaboratory上でのファイル操作に困った経験はありませんか?ドライブのファイルにどうアクセスできるのか、ディレクトリ構造はどうなっているのか、自動でアップロード・ダウンロードするにはどうしたらいいのか ... などなど。本記事は実際のコーディングでこれらをデモします。複数のやり方が存在しますが、少しでも参考になれればと思います。
Part1では、Gドライブとの接続の基本、そして、ファイルを新規作成し、アップロード、ダウンロードについて示します。次回のPart2では、表データや画像データの読み込みや表示など、もう少しバリエーションのある演習をしましょう。
Google Driveと接続
このコードで必要なクラスやモジュールをimportします。
まずGoogle Drive と接続します。つまりGoogle Driveのアクセス権限を与えます。
上記を実行すると、アカウントの選択画面に遷移するためのリンクが出ます。これに従い以下のようなページに移ります。ここでドライブをマウントしたいアカウントをクリックします。

Google Cloud SDK を信頼できることを確認する画面が出てくるので承認します。その後 verification code が表示されます。

Colabの画面に戻り、そのコードをもとの箱に貼り付けるとドライブにアクセスできる準備が整えられました。「ドライブをマウントしています」というメッセージが表示されるのでしばらく待ちます。
ファイルを読み込む
 ここでは、test_data.txt というテキストファイルを読み込みます。ファイルの中身はこんな感じです。
ここでは、test_data.txt というテキストファイルを読み込みます。ファイルの中身はこんな感じです。

GUIのボタンから選択します。txtファイルの各行をリストとして書き出します。

ファイルを新規作成し、ドライブにアップロード
リストの各要素をファイル名にし、その要素だけを含んだtxtファイルを作ります。リストの要素だけの数のファイうが出来上がります(5個)。

次にこれらのファイルをドライブ上にアップロードします。

ファイルのダウンロード
最後に5つのtxtファイルを一括ダウンロードしてみましょう。

パソコンのローカルに5つのファイルがダウンロードされたのが分かります。
いかがでしたか?
いったんドライブに無事に接続できるようになると、あとはパソコンのローカルのディレクトリと同じ感覚でファイルを「出し入れ」するなど操作できますね。ここで示したコーディングはなかなか覚えにくいものなので、実際は「こんなやり方があるのだ」ということを知っていただき、あとはメモしておいていつでも参照できるようにするといいですね。
ここまで読んでいただき、ありがとうございます。Part2も楽しみにしてください。
担当:ヤン ジャクリン(分析官・講師)
データの誤った解釈について考えさせられたこと
『「誤差」「大間違い」「ウソ」を見分ける統計学』, 2021, 共立出版 では、データを扱う中で、思わず勘違いしたり、ミスを犯したりするような場面が取り上げられています。読みやすくて、データ分析の実務に携わる方が一度は目を通しておくとよい本だと思います。
本書から、「そういえばこういう問題点があったなあ」と考えさせられたポイントを本記事で共有したいと思います。
「誤差」「大間違い」「ウソ」を見分ける統計学 / デイヴィッド・サルツブルグ 著 竹内 惠行 濵田 悦生 訳 | 共立出版
良い推定量とは何か
私たちが扱うデータは「観察できるもの」に限られます。これは母集団から抽出されたサンプルです。サンプルを使って母集団について「推定」を行います。つまり母集団の性質を「統計量」の算出を通じて知ろうとします。「よい推定量」とは、「どれくらい真の母集団を正確に表しているのか」と解釈することができます。一般的に「よい推定量」を得られるためには、サンプル数または試行回数を増やすことが考えられます。とはいえ、真の母集団を本当の意味で完全に知ることは出来ませんよね。
推定量の「良さ」を表す用語として以下がよく使われます。
一致性=平均が真の値に収束
不偏性=期待値が真の値に収束
効率性=他の推定量よりも分散が小さい
中心極限定理
実験データを解析する時は、当たり前のように「中心極限定理」を受け止めてしまうことがありますよね。昔の著名論文の中に、中心極限定理に従う分布として正規分布が挙げられていますので、その影響なのか、今ではよく考えずに正規分布に近似してしまうことがあります。しかし、使っているモデルは正規分布に近似してよいかどうかは注意しなければいけません。
個人的な話で恐縮ですが、私の博士過程の研究の一部として、粒子ビームの信号を測定器で測定していました。その信号の強さに相当する電圧値が測定対象でした。この測定値には誤差が必ず付き、その誤差を精密に評価することが私の研究の最も核心的な内容の1つでした。「一般的な見解」によると、実験で取得したサンプル数は十分に多かったので、周囲は「これは当然正規分布に従う誤差」とみなしていいでしょう... という風潮がありました。しかしそのうち、測定器の性質ゆえに、測定量の誤差はt-分布に従うことが判明しました。
(参考)https://www.icepp.s.u-tokyo.ac.jp/download/doctor/phD2014_yan.pdf
数学的な証明では、中心極限定理を受け入れるためには、「Liapunov条件」などの一定の条件が必要で、実際のデータがそのような条件を満たしているかどうかは不明ですし、手軽に証明することも難しいです。
因果と相関
「相関関係があるからといって因果関係があるとは限らない」とは良く言われるが、「因果」はそもそも定義が困難であることに注意が必要です。もちろん「原因と結果」という説明は可能だが、「原因」という単語を使わず、どういう条件を満たせば、「因果関係がある」と言えるのかという基準が必ずしも明確ではありません。
以下は因果関係を定義しようとした方々の発言例です。
「時間的にAがBに先行している」(哲学者のヒューム)⇨ 暫定的な定義であり、断定はできない
「ある意図的な力によってもたらされた結果」⇨ 限定的な条件下でのみ成立
ランダム化実験によって証明できる原因と結果 ⇨ランダム化実験でないと証明できない(例えば飲酒とガンの因果関係はこのような実験ができませんね)
記号論理学:「事象Aが起こらないときに事象Bが起こり得ない」
書籍の中で面白かったコメントとしては、「因果関係が確認されていません」と公で言い逃げする方には、「あなたによって因果関係は何ですか?」と聞いてみるといいですね。
統計量における外れ値の扱い方
トリム平均 * データを大きい順に並べて、中央のX%だけを採用して平均をとる。
- 中央値は、トリム平均の最も極端な例
考え方は理解できるが、これを自信を持って使えるのは限定的な場面でしょう。外れ値をたやすく切り捨てられている不安が残りますね。
ウィンザー平均 * データを大きい順に並べて、上側と下側のX%をそれぞれ、その境界に最も近い値に書き換えて、平均をとる
これはトリム平均に比べては、一応外れ値のサンプルの存在自体を数えているけど、それでも強引に丸められています。
ランダム化回答法
アンケート/調査では、違法行為や反社会的行為の経験など(例:万引きしたことがありますか)は答えにくいので正確な調査結果をなかなか得られません。こういう答えにくいYES/NO質問に対して、「質問への回答者しか結果がわからない」ようなランダムな方法(コイン等)で2つの質問から質問が決定され、それに対して回答者は正直に答えてくれるのだろう。質問の分配率から、本人を特定することなく、答えにくい質問にYESと答えた割合を推定する。
例えば、以下のような手順です。
まず、回答者にコインを投げてもらい表か裏か確認してもらう
表が出た人は、自分の答えがどちらであろうと「はい」と答える
裏面が出た人は、質問に対して正直に「はい」か「いいえ」を答える
「はい」と答えた人数から、回答者全員の半数を引いた値を推定値とする
データ = 真実を与えてくれるもの ではない
これは本当に当然のことですが、統計データを使用する上での大きな危険は、そのデータを取得するのにあたって、手順や測定法が遵守されていないなどで、正しくない方法で得られた値が混ざっていることを疑わないことです。書籍の中では、「暗いところでの温度測定を行う人が暗くて見えないからといってその場では数値を読む代わりに部屋に戻ってから数値を読み取っていた」が例として挙げられました。 まとめると、信頼できる分析結果を提供するためには、そのデータが取得された方法の適切さまで遡らないといけません。
データ捏造の発覚
捏造されたデータにおいて、羅列された数値の分散が、極端に揃っていることが多いそうです。1~9の数値の頻度が大きく異なる傾向にあります(特に最も最小桁の数値は完全にランダムになるはず)。ただし、実データをもとに偽造されたデータは、その点に気づかれにくくなります。また、ゴーストライターを用いた書物では、前置詞、形容詞、接続詞の使われる頻度を分析すると、違いが見えることが多いですとか。
担当者:ヤン ジャクリン(分析官・講師)
Snowflake速度を上げ課金額を下げるコツ
Snowflakeのメリットは、ウェアハウスの概念により、クエリの実行タイミングで速度と課金額を調整しやすい点です。この点は、他の列指向DBと比較して評価できる点です。例えば、夜間ジョブでは小さめのウェアハウスによりゆっくり時間をかけ処理をかけ低額を目指し、日中はユーザの待ち時間を最小にするために大きめのウエアハウスを選択します。待ち時間と費用のバランスを取ることができます。なお、このウェアハウスの変更では、データベースの移行は不要です。
ただ、データをロードする際、データとマシーンの動作を理解した上でウェアハウスを正しく設定しないと、費用と速度のバランスが悪くなります。大規模データを高速にロードしたいからと言って、大きめのウェアハウスを闇雲に設定すれば良いわけではないです。
例えば、数十GBの一つのファイルを毎日洗い替えでSnowflakeにロードするシナリオを考えます。ウェアハウスXSではロードに時間がかかりすぎるため、ウェアハウスをLに変更してみます。すると、ロード時間は夜間バッチ的にはOKであるが、意外とコストがかかることが判明したりします。XSとLでは立ち上がるマシーンとCPUの数が異なります。一つのファイルの場合、オーバーヘッド時間が発生することにより、無駄にマシーンが立ち上がっている可能性があります。そのような場合、一つのファイルをチャンクに区切って小さめの多くのファイルにすると、無駄が少なくなる可能性があります。エンジニアの話では、1つの大きなファイルより、100-250MBくらいのファイルに分割された状態で一括ロードするのがベストプラクティスということです。
参考資料
古幡征史
G検定取得したい方必見:2021#2の試験を振り返る
G検定を受験された方、現在受験勉強をしている皆さん、お疲れ様です。GRIの分析官・講師のヤンです。 今回は、G検定試験の最近の出題傾向や問題の特徴を解説するとともに、これから受験する方のために学習法を何点かお勧めしたいと思います。
この中で語る分析結果は、2021年7月17日に実施された2021年第2回(2021#2と略記)のG検定試験に基づいたものです。この2021#2の試験は少し特別です。なぜならば、2021年4月にディープラーニング 協会(JDLA)の方でシラバスが改定され、それに伴い、重点的に出題される分野も多少なり変わってきたからです。ということで、2021#2の試験はシラバス改定後の初めての試験です。また、今回から、G検定では合否だけではなく、出題分野ごとの得点率が受験者に知らせられるようになりました。さあ、出題の特徴と皆の感想を見ていきましょう。
事前に断っておきますが、実際、私も今回受験をしました。私は問題作成には関わっておりません。講師や執筆の業務を行う上で、新シラバスの特徴を正確に把握し、皆さんにより良い講座や読み物を提供していきたいがために受験したわけです。(※過去問は未公開なので、もちろんここでも実際の問題を公開しません。)
ということで、以下の順で話していきます。
■イントロダクション
「G検定とは」を知りたい方は、弊社監修のこちらの記事をご参考にしてください。
本記事ででも簡単に紹介しますね。 G検定(公式名:ジェネラリスト検定)は、一般社団法人日本ディープラーニング協会(JDLA; Japan Deep Learning Association;) が実施している資格試験です。その目的は、人工知能(AI)やデータサイエンスをビジネスに活用できる基礎知識を有しているかどうかを認定することです。(公式サイト: https://www.jdla.org/business/certificate/)
G検定の「G」が代表する「ジェネラリスト」(generalist)とは、「幅広い基礎知識を有し、適切な活用方針を決定して事業応用する能力を持つ人材」とJDLAでは定義されています。G検定はまさに、技術とその社会実装の双方の理解ができるビジネストランスレーターの育成を目指しています。
 参考:資格試験について - 一般社団法人日本ディープラーニング協会【公式】
参考:資格試験について - 一般社団法人日本ディープラーニング協会【公式】
AI人材育成の需要が高まるとともに、G検定はますます注目を浴びてきており、受講者数も全体的に上昇しています。「合格率」は 60~70% にあると 言えます。ただし、過去の試験問題や合格基準は非公開です。
 出典:資格試験について - 一般社団法人日本ディープラーニング協会【公式】
出典:資格試験について - 一般社団法人日本ディープラーニング協会【公式】
■出題傾向・最近何が変わったのか
G 検定で比較的多く出題される問題は以下だと感じています:
専門用語の定義、具体的な技術や分析手法の名称と内容
技術・手法の仕組みや特徴に関する理解
ディープラーニングを応用した最新技術の用語
AI を活用するための知見(社会・産業への影響、法的規制、倫理、現行の議論) → 多くの受験者が難しいと感じている
今回の試験より、全体的に、内容が「ハードな暗記を要する超難問」よりも、「実際に技術を業務に応用できる人材が知るべき」実践的な内容にシフトしているように感じます。例えば強化学習について理論的な深い部分に関する難問が減りましたね。本当にジェネラリストとして知るべき本質的な質問が増えてきました。
そして、細かいことですが、しばらく前は1つの問題文で(ア)〜(エ)の埋めるべき空欄が多数あって、同じ問題文は複数の設問にわたるような出題はなくなり、問題文が簡潔になり、逆に問われることの濃密度が上がったように感じます。
具体的に、今回出題が増えたなあ、と感じるのは以下の分野です。
モデルの解釈性
予測結果の解釈と根拠の明白化、AI における透明性、XAI(Explainable AI;説明可能AI)、ブラックボックス性問題、モデルを解釈するために使われる可視化ツールなど
AIを社会に実装する上で、起こりうる問題
個人情報の扱い、データの取得・利用・保管に関する規則、AIシステムへの攻撃(セキュリティ)、営業秘密など
この辺の内容が属する分野は、以前の試験では、どちらかというと純粋な法律の問題に近いものが出題されることが多かったです。例えば、特許権法や著作権法などの詳細を覚える必要がありました。今ではより「AIと社会を結びつける」ことに傾いた内容に切り替わりつつあるように感じます。
数学・統計学
相関係数、共分散、全微分と偏微分の違い、ベイズ推定、事後確率など
AIをビジネスに利用する上の考え方、プロジェクトの計画の立て方
モデルを学習するための学習データの使い方、データ拡張の正しい行い方、データセットの偏り、AIの実装から本番導入までの流れ、MLOps、PoC、共同開発など
上記以外に、以前の試験と相変わらず、かなり満遍なく ... ディープラーニングの仕組みの基本をいかに理解しているのか、それ以外の機械学習のアルゴリズム、自然言語処理、強化学習、画像生成、この中で、音声認識(今までは画像系だった...)について特に今回多く問われたのが印象的でした。
■SNSから見た皆さんの感想
「皆さんはどういう分野を難しく感じているのか」の感覚を持つ目的も兼ねて、Twitter上の声を収集し分析してみました。データ収集期間は、試験当日から2週間(7/17~30)です。
得点率から見た苦手意識
そこで、収集したツィートの中で、分野ごとの得点率に関与する内容を提供してくれた方の情報を可視化してみました。さらにそこには、ご好意で情報提供を受けた2021#2を受験した知り合い数名の点数も加えてあります。
以下で見せる分布は、合計63名の得点率を表したものです。
分野はこのように区切られています(情報提供に同意した受講者・匿名):

【注意】
横軸は「得点」ではなく「得点率」である
63名は十分なデータとはいえないし、当然(結果が悪く公表しない方など)バイアスがかかっているので、この分析結果は受験者全体の様子を正しく反映しているとは言えない
上記の制約があるものの、出題分野間の難易度のラフな相対評価の参考にはなるとは思う
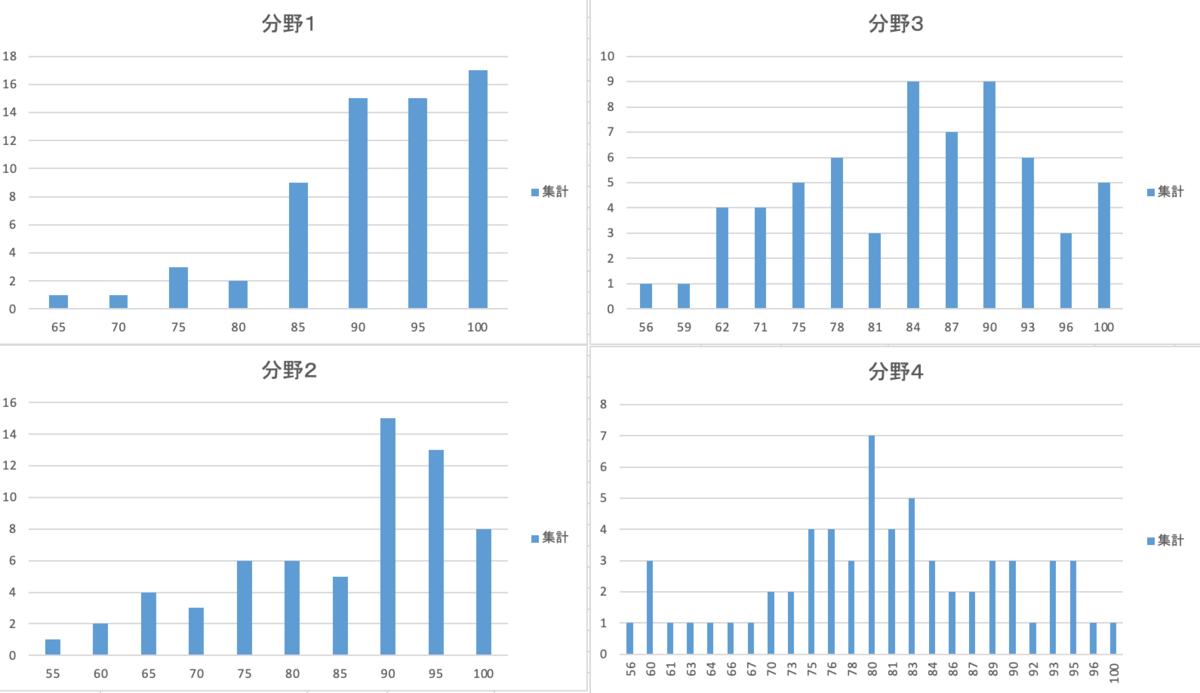
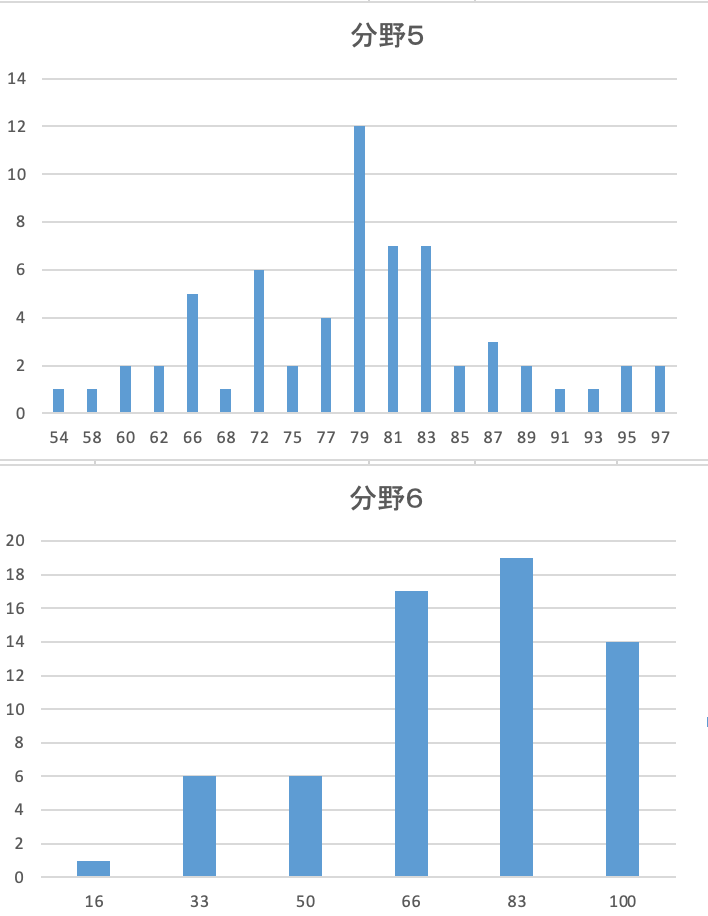
【グラフの分布に対する考察】
分野1(人工知能の定義・歴史などを中心に問う)と分野2(機械学習全般の考え方と個別の機械学習のアルゴリズム)に関しては、普段講座でも「しっかり学習すれば点数を取りやすい」とよく申し上げております。得点率からでも比較的高得点に偏っていることがわかりますね。
分野3(ディープラーニングの仕組み)や分野4(最新の研究分野)は、機械学習の中でも複雑で細かい、正しい理解がマストである設問内容の多いことから、分布は真ん中にピークする形に見えます。
分野5(AIの社会実装に伴う法律・倫理の問題、プロジェクトの進め方など)は、かなり難易度が高く感じられた方も多いでしょう。試験勉強の段階からこの分野に苦手意識を持つ方も多いと聞いております。それでも可能の限りこの苦手分野を克服することで、満点をとることは難しくても、合否が危うくなるほどの低い点数を免れます。
分野6(数学・統計学):比較的基本的、かつ過去の試験にも出題された問題が出されたからか、満点をとるのは難しかったようですが、全6問のうち半分以上は取れた、という方は少なくないでしょう。
ツイート投稿から抽出した受験者の声
以下引用です。
「G検定、そういえば、人物名は出題されなかったような。より実用的な問題重視になったってことかな?...」
「広く技術や法制度、社会動向の知識が問われて...」
「多分昨日のG検定は、「中国語の部屋」を忠実に再現した実験だった」
2020#3の試験の後も同様なSNSの分析をしました。
参考: Twitterのコメントから分析するG検定 - GRI Blog
G検定に関するTwitter上の最頻出用語を解説 - GRI Blog
一年前は、「とにかく難しかった」の声が多かったのです。今回は「超難問だ!」の発言がさほど多くはないのです。私が上記で述べた感想「法律や理論の中身に関する深い知識」よりも、「社会に悪い影響を与えずに、技術をビジネスなどに正しく応用するための知識」に出題アプローチを転向させていますね。これはとてもよい変化だと思いますし、今後はこのような試験を受験したい方も増えていくのでしょう。
■おすすめ学習法
過去の試験問題や合格基準は非公開であることから、どういう問題が解ければ合格できるのかという点について、十分な情報が得られない不安を感じるかもしれません。学習をサポートする情報はこちらのページや動画の中でお伝えさせていただいております。
データサイエンス|G検定対策講座(日本ディープラーニング協会) | アガルートアカデミー
最重要ポイントとしては、
時間内に全問回答することはきついと感じる方も多く、いちいちウェブ検索などで調べなくていいように、とにかく練習問題を徹底的にこなすアウトプットが、最も効率的な試験対策法です。
覚え方を極めることです。目の前の仮想的な質問者に「自分の言葉で相手に説明できるか」を試すのが有効ですよ!
「どうしても覚えきれない項目」だけをまとめたノート/フラッシュカード/チートシートを作り、本番直前に「これだけ見れば良い!」のような存在にしましょう。
講座の紹介
弊社GRIでは、難関資格予備校かつ法律の専門家の集団であるアガルートアカデミーにて、G検定試験対策講座を提供しております。
講座では、初めてディープラーニングを学ぶ方でも安心・充実して学べるように、初歩的な事項から入り、知識を1つひとつ丁寧に知識を伝えています。基礎をしっかり固めた上でG検定合格を達成したい方に最適な講座です。講師との質疑応答が可能な「コーチング制度」も用意しています。本書と合わせて、皆さんの学習に役に立てればと思います。
書籍の紹介
この度、10月2日より、GRIよりG検定の書籍を刊行することとなりました。今までの講座で受講生の方々を指導させていただいた経験に基づいて執筆したもので、これ1冊できっと皆さんを合格に導いていけるという自信作です。ぜひ手に取っていただけたら幸いです。
ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[明瞭解説+良質問題] | ヤン ジャクリン, 上野 勉 | 産業研究 | Kindleストア | Amazon
Point1 驚くほどわかりやすく覚えやすい解説!
G検定の試験は本来、ディープラーニングの知識をビジネスに活かす人材の育成が目的です。一方で残念ながら、多くの受検者は知識のハードな暗記にこだわりすぎて、受検後にはせっかく得た知識を忘れてしまいがちです。概念を「真に」理解していれば、暗記にさほど努力しなくても、知識がスッと頭に入り、定着しやすくなります。本書は読者に「理解」を届けることを目指しています。試しに、本書の本文に目を通してみてください。各分野の知識を体系的に、懇切丁寧に、まるで読者に語りがけるような口調で解説することを心掛けているのがわかります。アンサンブル学習、機械翻訳、深層強化学習、画像生成モデル…など難解と思える技術はじっくりとわかりやすく伝わるように説明しています。皆が悩む難問がこれでやっとわかる作りです。
Point2 本書のオリジナル問題は妥協しない質と量を誇ります!
本書のオリジナル演習問題は妥協しない質と量を誇ります。「奇抜な問題」と「簡単すぎる問題」(常識や消去法で解ける問題)を避け、「しっかり勉強すれば解ける良問」を中心に問題を設計しました。問題形式と難易度が本番試験に極めて近く、最新の出題傾向を的確に反映しています。巻末に模擬試験(200問)が付属されていることも本書の強みです。読者はこの模擬試験を予想問題として「リハーサル」することで、本番試験でのパフォーマンスの向上が得られるでしょう。もちろん、2021年4月にJDLAから発表されたシラバスの改訂にも対応しています。新シラバスで追加・強化された内容や問題を本書でも十分に扱っています。
Point3 赤シートを活用し、いつでも・どこでも、重要ポイントをラクラク覚える!
赤シートを利用することで、効率的に学習・問題演習できることが、本書の利用者の武器となります。
本文に関しては、最重要な(=最も出題されやすい)知識は赤字で書かれています。これらに赤シートを重ねると文字が消えます。この特徴を活用すると覚えるべき語句や箇所だけをピンポイントで確認しやすくなります。例えば、1回目は普通に本文を読み通し、2回目以降の復習では、文字を赤シートで隠しながら読み進めると、まるで問題を解いでいる効果が期待できます。しかも、場所を選ばず、例えば交通機関の中やちょっとした隙間時間にもさっと試験勉強できるのが魅力的です。
本文の学習後にすぐに取り組む章末問題に関しても、正解を赤シートで隠せるので、効率よく、一問一答の学習ができます。
プラスα G検定に合格後も長く使える!
著者は、多くの種類のデータサイエンスの講座を持っている他、データ分析とAI人材の育成を担うデータサイエンティスト集団の企業に所属しています。読者は、専門性を有する企業だからこそ伝えることができる知見を本書から得ることができます。G検定に出題される各概念を可能な限り、実務の現場の事例を使って説明しています。そのため、本書は、G検定に合格だけでなく、その後で実務で使う際までも長く使える一冊になっています。
■最後に、いつものメッセージ ...
G検定の多くは、基礎知識として知っていることが期待されている内容が出題されます。一方で、最新の技術動向を完全にフォローすることは難しいです。最新の技術や議論を問う問題を解けなくても、受験者は自信を失う必要は全くありません。まず、このような難問は合否に影響しません。それだけではなく、著者はこのような最新用語の出題はある特定の意図をもってなされていると思っています。 難易度の高い問題は、必ずしも受験の際に知識を持っていることが期待されているわけではありません。どちらかというと、「受験を機に、解けなかった問題については自発的に調べて知識を広げてください」というメッセージのように受け止めてよいと思います。ディープラーニングの応用は、完成された学問分野ではなく、日々技術が進化し、社会への実装がリアルタイムで試みられている領域です。それに伴い、学ぶべき内容が変わっていくのは当然です。G検定が認定するのは、「受検したタイミングにおける基礎知識」に過ぎません。一度合格しても、継続的に学習を続けなければ、最先端の知識をもっていると言えないわけです。
受験者へのインタービュで得られた知見をシェアしたいと思います。
「2020#3に初めてG検定に合格した後、半年経った頃にはせっかく覚えた知識の多くがなくなってきているのを感じていた。しかし二度目受験し合格すると知識の定着生が全くレベルが違うように感じた」
合格はゴールではなく、ジェネラリストとしてのスタートです。継続的に勉強を続ける姿勢それこそがジェネラリストに求められることだと思います。