自己情報量の発見法的導出
はじめに
情報理論の基本的な概念として、自己情報量があります。
自己情報量は、機械学習の分類モデルのアルゴリズムで登場する平均情報量の定義の基礎となっていたり、ここそこで現れてきます。ただ、抽象度が高いため初心者泣かせの概念です。
そこで、この記事では、以下の手順で自己情報量を理解していきます。
自己情報量の式の形を知らない前提で出発し、自己情報量が満たすべき性質を考察し、それを要請として表現します。
その上で、その要請を満たす式が自己情報量の式と一致することを見ます。つまり、自己情報量の式を導出します。また、どの要請がどう導出で効いていたかを観察します。
まとめとして、端的に自己情報量がどのような概念か表現します。
情報量が満たすべき性質と、要請
ここでは、情報量という言葉の意味からそれが満たすべき性質を考察し、その性質を要請として表現します。
情報量はびっくり度
まず、情報理論で情報量に関して知っていることを忘れていただきます。 一つの解釈として、情報量とは、ある事象を観測する際のびっくり度であると言えます。
これは、以下のような理由です。
起こることが全然分かっていないような、生起確率が小さい事象を観測するとき、得られる情報量(びっくり度)が大きい
逆に、起こることが確実に分かっているような、生起確率が大きい事象を観測するとき、得られる情報量(びっくり度)が小さい
より端的に言い換えると、以下のようになります。
生起確率の小さい事象を観測するとき、情報量(びっくり度)が大きい
生起確率の大きい事象を観測するとき、情報量(びっくり度)が小さい
そこで、これを満たすべき性質として捉え、以下のような要請をしてみます。
びっくり度の要請. は、確率
のみに依存し単調減少で、連続である
ただし、連続性の要請は導出のために補助的に追加しました。
情報量の加法性
情報量の「量」という言葉に着目してみます。
例えば、水を朝、昼
、夜
飲んだとします。この場合、合計で飲んだ水の量は、朝昼夜で飲んだ水の量の和
と一致します。 この性質は、物理では、相加性という名前で知られています。相加性は、水の体積だけでなく、体積・粒子数・エネルギー・質量などの「量」的な概念が持っています。逆に、温度・圧力・密度・濃度などの「量」的でない概念にはありません。
ここで情報量の話に戻ります。情報「量」というからには、相加性のような性質を持つべきです。つまり、事象が独立な複数の事象からなる場合には、部分ごとの情報量の和が全体の情報量と一致するべきです。そこで、以下のような要請をします。
加法性の要請. 2つの独立な事象について、
※情報理論の分野では、この性質を加法性と呼ぶようなので、この記事でも、相加性ではなく加法性と呼ぶことにします。
要請(自己情報量が満たすべき性質)のまとめ
これまでの議論をまとめると、以下の要請をすることにした、ということです。
びっくり度の要請. 自己情報量の関数は、確率
のみに依存し単調減少で、連続である
加法性の要請. 2つの独立な事象について、
自己情報量の式の導出
ここでは、上記要請を満たす式が自己情報量の式と一致することを見ます。つまり、自己情報量の式を導出します。
導出
ある事象が独立に
回起こる場合を考えます。
加法性の要請より以下が成り立ちます。
びっくり度の要請 (は
のみの関数)より、この式は特定の事象についてだけではなく一般的に成り立ちます。 つまり、以下が言えます。
を自然数とします。
で置き換えれば、 以下が成り立ちます。
これより、任意の正の有理数で
が成り立ちます。これは、びっくり度の要請 (連続性)より、任意の正の実数でも成り立ちます。
と置き、両辺を
で割れば、
となり、を満たす任意の実数
について
は一定となります。これより、自己情報量は以下のように導出できます。
ただし、この式はでも自明に成り立ち、
びっくり度の要請 (
は
の単調減少関数)より、
は任意の正の定数です。
このように任意性が残ることは、の底の値が
であろうと
であろうと本質的でないことと無矛盾です。
導出のおさらい
導出のポイントは以下です。
- 加法性の要請とびっくり度の要請 (
は確率
のみに依存)によって、任意の事象について
に比例することが言える
- びっくり度の要請 (
- びっくり度の要請 (
まとめ
結局、導出から次のように言えます。
自己情報量  は、事象の起こりにくさ「びっくり度」のみに依存する「量」である
は、事象の起こりにくさ「びっくり度」のみに依存する「量」である
これが本質的と言えそうです。
おわりに
自己情報量の確率的平均が、平均情報量(エントロピー)
です。
注意すべき点は、平均情報量が確率分布を引数とすることです。
ここでは触れていませんが、確率変数の値を伝えるときに最短の必要な符号長の平均長さが、平均情報量と一致するという性質があり、より「情報量」と命名される納得感があります。
「なんでXGBoostでは分類問題の学習に対数損失を使うんですか?」
先日M氏がO御大に質問していたのを聞いて、自分も気になったのでまとめてみました。
そもそも勾配ブースティングで目的関数はどのように使われる?
分類問題の話に入る前に、回帰問題を例にして勾配ブースティングの原理を簡単に解説します。 冒頭のM氏の質問ではXGBoostでしたが、ここ数年Kaggleなどでよく使われるLightGBMも含め、基本的なアルゴリズムは全部同じです。
勾配ブースティングの仕組み
個のデータ
と正解データ
が与えられているものとします。
今、勾配ブースティングモデルをと表すことにします。
簡単に言うと、勾配ブースティングは、決定木を縦に足し合わせたモデルで、各木を
として、以下のようにあらわすことができます。
ここで、は縦につなげた木の数(scikit-learnのGradientBoostingでいうn _ estimators)を意味します。
は各木のパラメータ(木構造、分割の際に用いる特徴量や閾値など)です。
学習プロセス
では、本の木をどう構築していくかですが、一言でいうと予測誤差にフィットさせた木を接ぎ足していきます。
例えば、本目までの木ができていたとして、その時点での暫定モデルを
と表すことにします。
この時のモデルと正解値との予測誤差にフィットさせて学習したものを、
番目の木とします。
このようにすることで、新しい暫定モデルは、
本目までのモデル
で間違ったデータを重点的に学習していく形になります。
損失関数を用いた解釈(勾配降下法)
前項では予測誤差を新たな目的変数として新しい木を作っていきましたが、これを、損失関数と勾配降下法という視点でとらえ直してみます。
まず、以下のように損失関数を定義します。
これは単純に誤差の2乗和ですが,モデルの予測値を変数とした下に凸な関数としても捉えることができます。
さて,ここからがポイントなのですが,予測誤差は,下記のように損失関数の勾配として捉えることができるのです。
したがって,「予測誤差に対して新たにフィットした木をモデルに追加する」という操作は、実は、勾配に沿った方向にモデル予測値を修正するということに相当するのです。
イメージ的にはこんな感じです:
この構図,どこかで見たことありませんか...? そう,勾配降下法になっているのです。

分類問題の場合
回帰問題では二乗誤差和を損失関数として勾配方向に沿って木を成長させていきました。 この方法は、二乗誤差和以外の損失関数でも適用できます。絶対誤差和や,二乗誤差をある閾値から線形に切り替えたHuber損失が使われることもあります。
同じ要領で、分類問題であっても損失関数さえ決めれば回帰の時と同じFormalismに落とし込むことができます。
問題設定
今までと同様,個の説明変数(特徴量)
と目的変数
が与えられているものとします。
ただし,今回の目的変数は、
個のクラスのいずれかとします:
。
対数損失関数の導入
分類問題を扱うにあたり,出力値は各クラスへの分類確率とします。
この分類確率は、理想的には正解クラス
のみ1をとり,それ以外は0を取るのが望ましいです。
したがってこの時,損失関数は、
- 全データの正解クラスへの分類確率
が1のとき,
- 正解クラスへの分類確率
は大きくなる
となるように設計するのが望ましいです。
そこで,今回の出発点であった対数損失(逸脱度)を導入します。
まず、各学習データについて、分類確率に対数をとったものを損失として定義します。
この値は、が1の時に最小値0をとり、確率0に近づくにつれ大きくなることが分かります。
これをN個の全学習データ分足し合わせたものが、下記の対数損失です。
この損失関数を使うことで、分類確率を直接あてに行く場合と比べ、誤分類時の損失が強調されるので学習しやすくなります。
学習の進め方
前項で定義した対数損失をもとにモデルの学習を進めますが、これには回帰の場合と同様に損失関数の勾配を新たな目的変数として逐次新しい木を構成していきます。
ただし、正解ラベルや確率そのものを当てに行くのは難しいので、いったん回帰モデルを構築してから確率に変換するという方法をとります。
ステップ目までのモデルを
とします。ここで注意点ですが、多値分類の場合は各クラスごとに異なる木を構築し、別々に学習を行います。
このモデル出力値に、二値分類の場合はlogistic関数を、多値分類の場合はsoft max関数を噛ませることで、確率に変換します。
二値分類
多値分類
これを用いると、対数損失とその勾配は以下のように書けます。
二値分類
損失関数:
勾配:
多値分類
損失関数:
勾配:
はクロネッカーのデルタといって、
の時のみ1, それ以外では0をとります。
この勾配を目的変数とし新しい回帰決定木を構築してそれまでのモデル
に足し合わせることで、新たなモデル
を作ります。
ここからまた新たな対数損失の勾配を求め、モデルを更新し、...というステップを繰り返していきます。
まとめ
所々細かいところは端折りましたが、以上が勾配ブースティングのアルゴリズム概要になります。
冒頭の「なぜ対数損失を使うのか?」という問いに戻ると、以下のような回答が挙げられるかと思います。
- 勾配ブースティングでは内部的には回帰決定木を用いて予測を行う
- 分類確率に対数をとった
に着目することで値域が
となり、不正解時の誤差が強調される。
対数をとらずに分類確率をそのまま使ってといった量を損失関数として学習を行うこともできなくはないかもしれません。
しかし、
自身は
]区間の値しか取れないので、対数誤差と比べると学習しにくくなるように思います。
ちなみに、対数損失以外に指数損失が使われることもあります。 特に二値分類で指数損失を用いる場合は、AdaBoostという別の手法と一致することが知られています。
参考文献
T.Hastieほか、統計的学習の基礎 ―データマイニング・推論・予測―

- 作者:Trevor Hastie,Robert Tibshirani,Jerome Friedman
- 発売日: 2014/06/25
- メディア: 単行本
通称カステラ本。 標準的な機械学習アルゴリズムが網羅的に書かれた辞書のような本です。 分厚いですが、記述は丁寧なので気になるところをつまみ読みするにはもってこいです。
特に勾配ブースティングを含めたツリー系アルゴリズムが数理的にきちんと書かれた書籍はこれ以外知りません。
scikit-learn
Python機械学習ライブラリの定番です。ドキュメントやGitHubにあがっているコードを読みながら動作を辿ってみると理解が深まります。
GRIブログの始まり
はてなブログの使い方
株式会社GRIは「データ分析で社会をより良く」をテーマに掲げるデータサイエンス系の会社です。
分析官たちは日ごろから案件を通して研究開発を進めていますが、 その過程で生まれた分析ノウハウなどは現状、様々な場所に散在してしまっています。 GRIではConfluence、Github、Colaboratory、Slackなどのサービスを利用しており、 他のメンバーと共有したい情報はその文脈に合わせてサービスを使い分けています。 一見、効率的で賢い方法にも思えるのですが、情報が散らばった状態では本当に価値のあるストーリーにまで昇華しないことも多い気がしています。 直近の作業を進める上では効率的なコミュニケーションがとれるのですが、 知識の積み上げが部分的になり、長期的にみたときの成長曲線にブレーキをかけるのではという危惧があります。
そこで、分析官が気軽に書けるブログサイトを開設することにしました。 WixやWordpressなども試しましたが、
- 前者はマークダウン記法が使えなくて数式の記述が面倒
- 後者はTableauやJupyter NotebookのEmbedが面倒
だったりと、分析官が気軽に書ける環境ではなかったので、はてなブログを今は試しています。
はてなブログの書き方
基本は「マークダウン記法」
こちらの記事を参考に、デフォルトの「見たままモード」から「マークダウンモード」に変更しました。 Jupyter NotebookやGithubで書き慣れているというのが最も大きい要因でした。
ソースコードの書き方
はてなブログではシンタックス・ハイライトのソースコードを記述することが可能です。
import pandas as pd df = pd.DataFrame(range(10), columns=['colA'])
数式の書き方
はてなブログでは以下のように記述することで、Texの数式を表現可能です。
[tex: (TeX記法)]
たとえば、
[tex: x + y = z]
と書くと、
のように表示できます。 ただし、はてなブログ特有のクセがあるようなので、以下の記事などを参照してください。
Tableauの埋め込み
分析官はデータの可視化にTableauを使うことも良くあります。 はてなブログではTableauのEmbedコードを直接貼り付けるだけで、以下のように表示することができます。
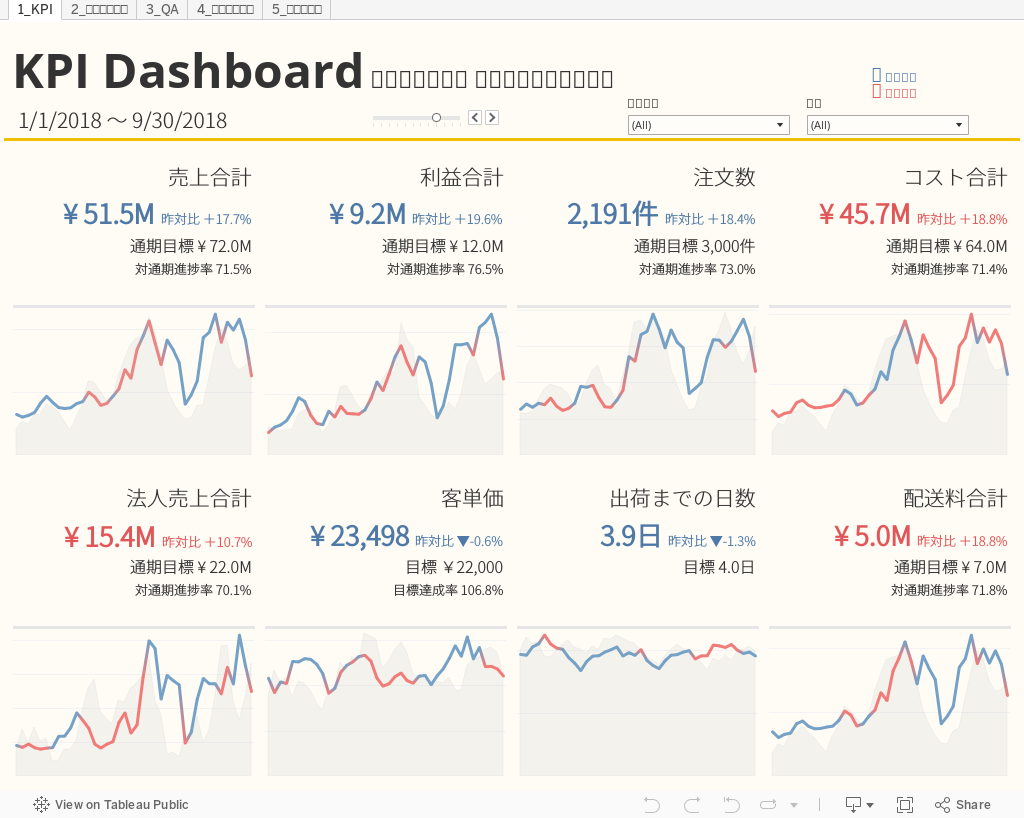
Power Pointの埋め込み
分析官のレポートはPowerPointになることが多いので、それを埋め込めると記事を書くハードルが下がる場面もあると思います。 以下はこちらの記事を参考にして、Google Slideを埋め込んだ例になります。
Jupyter Notebookの埋め込み
GRIでの分析のプライマリ言語はPythonになっているので、Pythonの話題はとても多いです。 PythonにはJupyter Notebookという対話形式で分析の試行錯誤ができるパッケージがあり、これが分析の過程や結果を共有するのに非常に便利です。 はてなブログでは、この記事で紹介されているような方法でNotebookを表示することが可能です。
まとめ
はてなブログでは分析官の良く使うツールの埋め込みや表示がとても簡単にできることが分かりました。 知見を蓄積・共有するため、ブログ記事をどんどん書いていこうと思います。