サブスクリプションがブームとなった訳
「サブスクリプション」という言葉が浸透した現在ですが、改めてなぜブームとなったのか自分なりの意見をまとめてみました。
定額料金を支払い利用するコンテンツやサービス。商品を「所有」ではなく、一定期間「利用」するビジネスモデルのこと。
消費者の価値観の変化
消費者の価値観が変化していることは、色々なところで耳にする話しであるかと思います。モノを「買って持つこと」でサービスを受けることから、「持たずに共有すること」でサービスを受けることに考え方が変化しています。
ではなぜこのような変化が起きたのでしょうか。大きく2つの理由があると考えています。
(1)「買って持つこと」の価値が薄れた
(2)「持たずに共有すること」でサービス受けることができる環境が整った
(1)「買って持つこと」の価値が薄れた
「買って持つ」ことの価値が薄れた理由の一つ目は、良い品質のモノが世の中にあふれ、品質の高いモノを持つこと自体が、レアではなくなったことです。事業者の立場で考えると、モノの品質で他社と差別化がしづらくなったため(差別化できてもすぐ真似されてしまうため)、違う観点で強みを作っていく必要があります。 また、不景気の影響もあり、多くの消費者が将来に不安を持ち、お金をなるべく消費しないマインドを持っていることも「買って持つ」ことの価値を下げている要因だと思います。
(2)「持たずに共有すること」でサービス受けることができる環境が整った
(1)に対して、「持たずに共有すること」でサービス受けることができる環境が整ったことがポジティブな面として考えられます。インターネットが発達し、ネットを介して無形物のサービスを受けられるようになったことや、以前に比べ物流のインフラが発達し、小ロットで多頻度の配送ができるようになったことも要因でしょう。
上記の理由から、共有してサービスを提供するサブスクリプションがブームとなり、サービスが増えてきていると考えています。
時系列を基本要素に分解する
時系列データをトレンド、サイクル、季節、残りの各要素に分解する手法についてまとめていきます。 なお、こちらの記事を参考にしています。
時系列データは加法モデルを用いると一般的に以下のように表されます。
ここで、は時刻
におけるデータ、
は季節成分、
はトレンドとサイクルを合わせた成分(これ以降は単にトレンド成分と呼ぶ)、
は残差成分を表しています。
時系列データを各要素に分解することで、興味に基づいた最適なデータを取得することが可能になります。例えば、失業データでは一般的に季節調整データと呼ばれる時系列データから季節成分を取り除いたデータが使われます。これは、一般的に失業データを見る際には、景気後退のような季節によらない変動のみに関心があるためです。その他にも、傾向の変化に関心があるのであれば、トレンド成分
を見るなど、要素に分解することで最適な観測が行えるようになります。ここからは、各要素に分解するための手法について見ていきます。
古典的分解
古典的でシンプルな手法です。各要素は以下の3ステップから求められます。
Step1: 移動平均を用いて時系列データからトレンド成分を抽出する
Step2: 時系列データからトレンド成分を取り除いたデータに対して、すべての季節の平均を取り、季節成分
を取得する
Step3: を計算し、残差成分
とする。
古典的分解手法では、移動平均によりトレンドを求めているため、最初と最後の一部の要素を求めることができません。また、トレンドがなめらかになりすぎることにより、残差にトレンドが残ってしまうといった問題やどんな波形に対しても季節成分が平均化されてしまうといった問題などがあります。
ヨーロッパでの電子機器の注文数のデータに対しての例を見ていきます。

X11分解
X11は古典的分解手法を発展させた手法です。この手法では、すべてのデータに対してトレンドを求めることができます。さらに、季節成分が時間によって少しずつ変化することが可能になっています。先ほどと同様の例を見てみると、トレンドの急激な下降をよくとらえています。

SEATS分解
SEATSはARIMAを利用したモデルです。この手法は四半期あるいは月次データにのみ利用可能です。
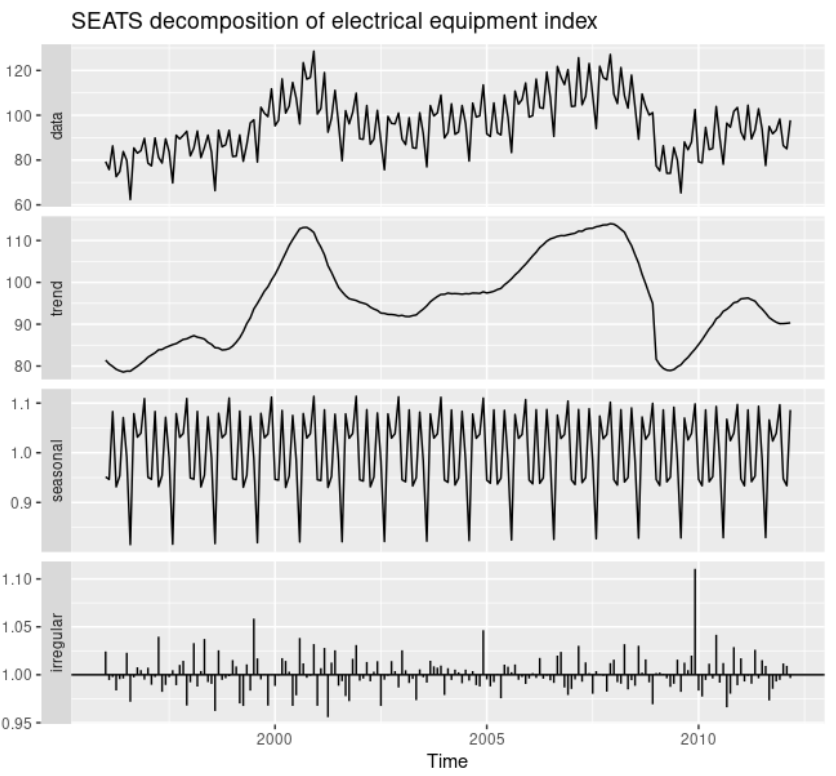
STL分解
STLはロバストな手法です。どんなタイプの季節性に対しても利用することができます。また、季節成分が時間によって変化することができます。

背景差分
動画から移動している物体や人物だけを検出したいと思う場面は多くあると思います。そんなときには背景差分やフレーム間差分の手法が役に立ちます。 今回は背景差分やフレーム間差分について紹介しようと思います。以下のページを参考にしています。 https://www.dendai.ac.jp/crc/about/forum/e5vdec000000dvk0-att/forum05_04.pdf https://kimamani89.com/2019/04/30/post-420/ https://www.cs.utexas.edu/~grauman/courses/fall2009/slides/lecture9_background.pdf
フレーム間差分
フレーム間差分は時間差のある3枚の画像から移動物体を抽出する手法です。

まずは画像I1とI2の差分を取ります。同様にI2とI3の差分も取ります。

その2つの論理積を取ると、移動物体のみを抽出することができます。

フレーム間差分の優れている点は背景モデルを作成する必要がない点にあります。 時間変化に対して移動物体の移動量が大きく、かつ背景の変化が小さい動画にこの手法は向いています。
背景差分
フレーム間差分よりも背景の変化に対応できるのが背景差分の手法になります。 背景差分のシンプルなモデルでは、複数のフレームから各画素値に対してガウシアンモデルを構築します。 下のグラフでは赤が背景モデル、黒が前景モデルを表しています。

新たなフレームの各画素値はこれらのモデルから前景or背景が判断されます。 この手法では新しいフレームが入ってくる度にモデルを更新することができます。 ただし、設定すべきパラメータが多い点、背景の急激な変化には対応できない点などが課題としてあります。
機械学習で使える大規模な画像データセット
大規模なオープン画像データが必要になったので調査してみました。
ImageNet
オープンデータの中で特に有名なデータセットです。 かなり細分化されており、大量のクラスが存在しています。
WordNetに紐づけられており、階層構造になっているので、目的の画像が探しやすくなっています。
Poppyを選択してみました。Poppyだけで16クラスも持っています。

ランダムにクラスを選んで、アノテーション情報に関しても確認してみます。 体感的には1/3くらいがバウンディングボックスの情報を持っているようです。
Open Images Dataset
Googleが出している画像の大規模データセット。クラス数はそこまで多くはないようです。
Appleを選択してみます。
TypeをDetectionにするとこんな感じ。バウンディングボックス付きの画像が表示されました。

個別では認識できていないものも多そうですが、集合体だと認識されたものに対してはApple(Group)というタグがつけられているようです。
TypeをSegmentationに変更してみます。リンゴの領域が塗りつぶされた画像が出てきました。

個別で識別できているもののみがSegmentされているようです。
COCO dataset
chairとwine glassを選択して画像を検索してみます。
chairとwine glassの両方が含まれている画像が数多くでてきました。
画像から抽出されたものが画像の上に表示されています。
さらに画像に対するCaptionも生成してくれています。

もう一枚見てみます。

奥にいる人などはSegmentされていないようですが、手前にあるものは高い精度でSegmentされています。
おわりに
今回は登録なしで気軽にデータを確認できる3つのデータセットを調査しました。
今回紹介したもの以外にも動物の画像だけのものや工業製品の画像だけのものなど条件を絞ったデータセットは数多くありそうです。
決算短信と有価証券報告書の違いとは?
他社のコーポレートサイトからIR情報を見ようとしたとき、どの書類を参考にすべきなのか、わからないことがあるかと思います。
上場会社が投資家向けに作成する決算資料として、「決算短信」と「有価証券報告書」があります。どちらも会社の財務状況に関する情報が載っていますが、どのような違いがあるのでしょうか。
| 名称 | 決算短信 | 有価証券報告書 |
|---|---|---|
| 根拠 | 証券取引所のルール | 金融商品取引法 |
| 開示期日 | 決算日から45日以内 | 決算日から3ヶ月以内 |
| 情報量 | 少ない | 多い |
| 期待されるもの | スピード | 正確性 |
決算短信
決算短信は、証券取引所のルールにのっとって作成し、証券取引所に提出される書類です。決算短信の重要なポイントは、開示の「スピード」になります。開示する情報量は重視されない代わりに、素早く情報を開示することが求められます。
決算日から45日以内の開示が義務付けられています。日本では3月を決算月と定めている会社が多いため、ゴールデンウィーク頃に上場会社の決算短信が開示されるケースが多いです。
有価証券報告書
有価証券報告書も、上場企業は提出を義務付けられている決算に関する書類になります。 有価証券報告書は、金融商品取引法にのっとって作成されます。こちらは上場会社だけが対象ではなく、一定規模以上等の条件に該当する会社が対象となります。
有価証券報告書の重要なポイントは、情報の「正確性」になります。開示されるスピードは重視されない代わりに、正確な情報を開示することが求められます。そのため、監査法人という社外の専門家が「この財務情報は適正である」とお墨つきを与えた情報が開示されています。
決算日から3ヵ月以内に開示することが義務づけられています。したがって、3月決算の企業の有価証券報告書は、6月下旬にならないと入手できません。
企業のIR情報を調べる際には、ご参考にしてみてください。
上野
pythonのlocustで負荷テストを行う
大量のアクセスがきてもサーバーが落ちないこと。これは大事なデータを扱うサービスの重要な要素であったりします そんなことの無いようにリリース前に負荷テストをしようぜということになりました
今回はpythonのlocustという負荷テストツールを使ったメモです
誰が使ってる?

locustの公式ページにはGoogle, mozilla, amazonなどが使っているようです
インストール
# pipから
pip install locust
※Dockerでも公式イメージがあるので、その場合はローカル環境へのインストールは不要です
# versionの確認 locust -V # locust 1.5.2
私の環境では1.5.2のバージョンになります
コード
公式のTutorialから
# locustfile.py import time from locust import HttpUser, task, between class QuickstartUser(HttpUser): wait_time = between(1, 2.5) # 1ユーザーのページ滞在秒数の範囲 @task def hello_world(self): self.client.get("/hello") self.client.get("/world") @task(3) # 数字はtaskの重み def view_items(self): for item_id in range(10): self.client.get(f"/item?id={item_id}", name="/item") time.sleep(1) def on_start(self): self.client.post("/login", json={"username":"foo", "password":"bar"})
- 実行後、各メソッドはランダムにリクエストされる
- 重み task(3)と入れることで、hello_worldメソッドよりもリクエストが単純に3倍呼ばれる率が高くなる
- on_startはユーザーのリクエストの最初に行われるメソッド. 上記はon_startでページログインを行なった後、hello_workd, view_itemsそれぞれのメソッドを実行する
実行
locust -f locustfile.py
※Dockerの場合
docker run -p 8089:8089 -v $PWD:/locust locustio/locust -f locustfile.py

ではブラウザからhttp://0.0.0.0:8089にアクセスしてみます

- Number of total users to simulate
- 最大の同時接続数
- Spawn rate
- 1秒あたり何ユーザー増やしていくか (最初から最大数にしたい場合は”Number of total users to simulate”と同じ数字にすればよい)
- Host
- リクエスト投げるドメイン名 (例: https://www.google.com)
イメージ図


リアルタイムで動作確認ができます また、プロセスを止めた時、コンソールにサマリー結果を出力してくれます

図ではきれいな数字ですが、実際にはステータスが500(サーバーダウン)になる閾値を見つけてインスタンス数やスペックの調整をしたりしました
参考
Locust Documentation — Locust 1.5.3 documentation
負荷テストツール、Locustで遊ぶ
higashi kunimitsu
「ライゾマティクス」とデータ可視化
先日、東京都現代美術館で実施している「ライゾマティクス_マルティプレックス」展を見に行ってきました。 現在多くの美術館は完全予約制となっており、会話もなく比較的安全な娯楽かと考えておりますが、同展は若者を中心に思ったより人出があった印象です。
「ライゾマティクス」というのは「芸術と技術の両方を使用して大規模な商業および芸術プロジェクトを作成することに専念している日本の会社(Wikipediaより)」となります。 昨今テクノロジーの発展とともに電子デバイスを利用したデジタルインスタレーションが多くなってきましたが、ライゾマティクスはリオ・オリンピックの閉会式やPerfumeのステージ演出を行ったことで有名で、最新のテクノロジーを使い表現する技術力とアイデアにおいてチームラボ同様日本でトップクラスの会社だと思います。
さて、ライゾマティクスの真鍋大度氏らが技術支援で参画したデータ可視化の力が最もわかりやすい作品、個人的には以下かと思います。
Sound of Honda / Ayrton Senna 1989 www.youtube.com
鈴鹿サーキットで亡きアイルトン・セナが叩き出した最速RAPの走行データをつかい、実際の鈴鹿サーキットに光と音を出すデバイスを設置して再現した作品です。 数値データからそこにあたかも走っているかの感覚を引き起こすこの作品は、世界から絶賛され多くの賞を獲得しました。
ここで興味深いポイントはその見せ方で、例えば提供データから「CGを使った映像を作ろう」といった感じでデータの可視化をすると、おそらくどんなに精巧なCGでもここまでの感動を得ることは出来なかったのではないでしょうか。 ときには大胆に情報を削ぎ落とし、重要な点だけで構成することでよりわかりやすく「可視化」ができるというケースではないかと考えます。
また同展には様々な問題で不透明な部分が多いCryptoArt(暗号資産化されたデジタルアート)の売買状況をリアルタイムで可視化することで市場を目に見えるようにした「NFTs and CryptoArt-Experiment」などの作品がありましたが、いちばん目を引いたものは作品の中でも最も大きなもので、暗闇の中で物理的な構造物にころがりながら発光するボールの軌跡をみせる作品「particles」でした。 なかなか説明が難しいので、以下の動画や資料を見ていただければと思います。
particles at YCAM
particlesの技術資料 http://daito.ws/dl/particles_0406.pdf
particlesの制作話 www.cbc-net.com
アート作品なのである意味「だからなに」となってしまいがちですが、この作品も素材やデータをどう切り取り組み合わせるかで、「人がより見ていたいという欲求を引き出せる」というものに仕上がっていると感じました。
このようにライゾマティクスは最新のテクノロジーを駆使して、行動履歴やデバイスから得られたデータなどから「見えないものを可視化」することにより見えてくるものを追求している会社で、生み出す作品や可能性は目を見張るものがあります。 弊社もサービスの一角として「データをどう見せるか」のお仕事を多く頂いておりますが「見せたいものの本質は何か」を踏まえ魅力あるご提案をできればと考えております。