【5分講義・深層強化学習#3】今ホットなA3Cアルゴリズム
強化学習、そして強化学習をディープラーニングと組み合わせた深層強化学習は、AIを学ぶ上での難題の1つです。本記事では、強化学習の学習法のイメージを持っていただくために、強化学習の数多くのアルゴリズムの中でも有名なA3C(Asynchronous Advantage Actor-Critic)を紹介します。強化学習の基本概念については、別の記事で紹介します。
■A3Cアルゴリズムとは
A3Cは、2016年にDeepMind社のVolodymyr Mnih (ヴォロジーミル・ムニ)の研究チームによって提案されました。
原論文:https://arxiv.org/pdf/1602.01783
A3Cの特徴は、複数のエージェントが同じ環境で非同期に学習することです。名称"Asynchronous Advantage Actor-Critic"にある3つの”A”は「Asynchronous」と「Advantage」と「Actor」を表し、”C”は「Critic」を表します。「Asynchronous」は「非同期」という意味、つまり複数のエージェントによる非同期な並列学習を行うことです。「Advantage」とは、複数ステップ先を考慮して更新することを指しております。そして、ActorとCriticに関しては、Actor-Critic手法と関わっています。
一瞬話が脱線します。Actor-Criticとは強化学習の学習のアプローチの1つです。行動を決めるActor(行動器)を直接改善しながら、方策を評価するCritic(評価器)を同時に学習させます(図1)。方策ベースと価値ベースを組み合わせた手法です。Actor-Criticを用いると報酬の揺らぎから影響を受けにくくなり、学習を安定化および高速化できるメリットがあります。
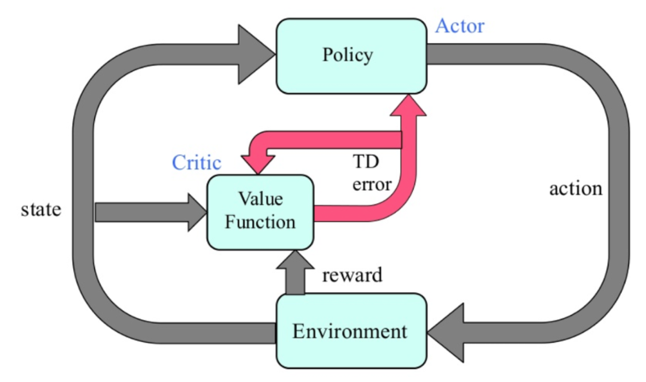
■A3Cによる非同期学習の詳細と利点
各エージェントが並列に、自律的にrollout (ゲームプレイ) を実行します。そこで計算した勾配の情報をに基づいて、「それぞれのタイミング」で共有ネットワーク(global network)を更新します。そして、各エージェントはそれぞれ定期的に自分のネットワーク (local network) の重みを共有ネットワークの重みと同期します。図2にA3Cの並列学習の仕組みが表されています。

では、並列分散エージェントを用いて学習を行うことのメリットは何でしょうか。
1つは、ネットワーク全体と重みを共有しつつ、並列分散的に学習しているため、学習が高速化できることです。
もう1つは、学習を安定化できることです。
経験の自己相関による学習の不安定性は強化学習分野の長年の課題でした。深層強化学習といえばDQN手法が有名です。DQNではExperience Replay (経験再生)を用いて学習の安定化を実現しています。しかし、経験再生はDQNのような「方策オフ手法」でしか使えません。これに対して、「方策オン手法」であるA3Cは、経験の自己相関を低減するために、エージェントを並列化する工夫をとっています。
A3Cの難点
一方で、A3Cの難しいところは以下です。
強化学習の実装にはPythonがよく用いられますが、Pythonのプログラミング言語の特性上、非同期並列処理を行うのがやや面倒です。また、同時並列的に学習するため、A3Cの実装はそれなりに大規模な計算リソースのある環境が必要です。
A3Cの後にA2Cという手法が発表されています。A2Cは同期処理を行います。各エージェントが中央指令部から行動の指示を受けて一斉にワンステップ進行し、中央指令部は各エージェントから遷移先状態の報告を受けて次の行動を指示します。したがって、ある程度リソースが節約されます。また、Pythonでも実装しやすいのです。A2Cの性能がA3Cに劣らないことがわかったので、よく使われるようになりました。
後続の記事では、A3Cのアルゴリズムをさらに詳細に説明していきます。それを読むと原論文の主張も理解しやすくなりますので、是非目を通してみてください。
ここまで読んでいただきありがとうございました。それでは、次回またお会いしましょう。
記事担当:ヤン・ジャクリン(分析官・講師)
【5分講義・自然言語処理#5】GPT-3活用の大変さとは
以前の記事では、自然言語処理における事前学習と転移学習、そして、そのための手法としてBERTとGPTを紹介しました。
上記の記事で説明したように、GPT系列の中で、特に最新のGPT-3は、「人間らしい」文章を生成するなど、驚くほど高度なタスクを実行できます。しかしながら、GPT-3の利用に関しては社会的な問題とリソース的な問題が報告されています。本記事では代表的な課題を説明していきます。
GPT-3の活用に関する課題
■社会の安全に関する課題
GPT-3は、「人間らしい」文章を生成する可能性を保持しているゆえに、偽物のブログやスピーチの作成・発信に悪用されることが懸念されています。そのため、セキュリティを守ために、GPT-3は完全オープンソースとして提供されておらず、Open AIのAPIを介してのみ利用できるようになっています。また、このAPIの利用には申請が必要です。
https://openai.com/blog/openai-api/
■機能の限界
GPT-3は驚くほど高品質な記事を生成できるが、その記事の文法が正しくても、意味的に違和感や、文章の内容における矛盾を感じることが時々あります。また、GPT-3は「物理現象に関する推論」ができないことも指摘されています。例えば、「照明をつけたら眩しく感じますか」という質問には答えにくいです。 これらの問題は、GPT-3が前の文章にある単語との関係性を学習ことに長けてはいますが、人間のような社会の慣習や常識を認識できないことに起因します。Part1で習ったシンボルグラウディング問題とも関連していますね。
■学習や運用のコスト
膨大なパラメータを使用したGPT-3の事前学習を現実的な時間内で実現するためには、非常に高性能なGPUを必要とします。逆に、最も低い市場価格のGPU環境を使用することを想定した場合、数百年かかってしまうと言われています! 訓練に要する計算量(時間、リソース)は、モデルのサイズ(パラメータの数)とともにスケールします。下図からわかるように、毎秒1ペタ回の演算を行う場合、 GPT-3 175Bの学習には数年以上を要します。

モデルサイズを含む自然言語処理モデルの課題に関しては、是非以下の記事もご覧になってください。
ここまで読んでいただきありがとうございました。それでは、次回またお会いしましょう。
記事担当:ヤン・ジャクリン(分析官・講師)
【5分講義・自然言語処理#4】最新のGPTを知りましょう
前回、自然言語処理における事前学習と転移学習に関して、以下のように書きました。
【10分講義・自然言語処理#3】事前学習と転移学習・そしてBERTも - GRI Blog
最新の事前学習モデルとして、OpenAI*1が開発したGPT(Generative Pre-Training)系列のモデルが有名です。本記事では、GPTの技術について紹介します。
GPT-nモデルの全体的説明
GPTは、過去の単語列から次の単語を予測するように学習を行います。文章の内容や背景を学習する上で高い性能を発揮し、幅広い「言語理解タスク」に対応できます。例えば、文章分類に使われる評判分析(sentiment analysis; 入力文がpositiveかnegativeかneutralかを判定)、質問応答(question answering; 常識推論、質問文が与えられたときに、適切な回答を選択肢の中から選ぶ)、意味的類似度(semantic similarity; 2つの文が同じ意味かどうかを判定)などが挙げられます。
初代のGPT、GPT-2、GPT-3の順で相次いでバージョンアップしていきました。これらを本記事でGPT-nと呼んでいます。下図からもわかるように、GPT-2とGPT-3は初代のGPTに比べてパラメータ数が桁違いに増加しています。初代GPTはパラメータ数が1.1億、2019年に発表されたGPT-2は15億、2020年のGPT-3は1750億と、GPT2の約117倍以上になります!モデルのサイズアップに伴い、長い文章を生成する能力や高度なタスクに対応する能力も上がっていきました。
本節の残りでは、GPT-3を中心にお話していきます。

GPT-3による文章の自動完成
GPT-3の仕組みについて特筆すべき点を紹介していきます。
前述の通り、GPT-3のパラメータ数は1750億個もあり、モデルを学習するために約45TBにもなる大規模なテキストデータ(コーパス)を事前学習します。この巨大データセットには何千億もの単語や語句も含まれています。学習データの多くはウェブからデータをスクレイピングしたものや電子化された書籍やウィキペディアから来ています(下表)。 出典:https://arxiv.org/abs/2005.14165

GPT-3の構造は、トランスフォーマー(Transformer)を基本としています 。エンコーダを持たず、トランスフォーマーにあるデコーダと似た構造を持つネットワークになっています。トランスフォーマーは2017年にGoogleが発表した(当時は主に機械翻訳のための)言語モデルです。以下の記事の説明がわかりやすいです。
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
GPT-3では「ある単語次に来る単語」を予測し、自動的に文章を完成できるように、教師なし学習を行います。例えば、以下のような単語系列の次に来る単語を予測するケースを考えましょう。
”I”、”need”、”ice”、”because”、”my”、”drink”、”is”
出力値は「その単語が次に来る確率」です。単語の確率が、”hot”:50%、”warm”:30%、”good”:15%、”cold”:5%になったと仮定すると、”I need ice because my drink is”の後に続く単語は”hot”が尤もらしい候補で、”warm”はまあまあ可能性がある、”good”や”cold”は確率が低いと推測できます。
GPT-3は何がすごいのか
■その1:幅広い言語タスクを人間の知能を思わせるような高い精度で実現できることがすごい
ビッグてテキストデータセットを用いて巨大なネットワークを学習しているだけに、GPT-3は今までにない精度で、入力された言葉に続く言葉を推測することができます。そのため、あったかも人間が書いたような文章も自動生成できたりします。文章を生成するだけでなく、翻訳、質疑応答、文章の校正、文章の穴埋めなど、実に様々なアプリケーションで使用されています。例えば…
・自然言語からソースコードを生成する ・楽譜を創作する ・デザインを生成する
(参考)https://gptcrush.com/resources/
オフィスの中で、GPT-3を活用してマニュアル、提案書、報告書、会議議事録など業務上必要な書類を自動生成することが想像できますね。
■その2:数少ない事例で言語能力を習得できることがすごい
GPT-3に文章の書き出し、プログラミングコードの最初のたった数行を与えて実行するだけで、様々な用途に合わせて続きを自動生成できます。このような少数の事例で学習できるAIを「Few Shot learning」と呼びます。原論文のタイトルはまさに「Language Models are Few-Shot Learners」です。
参考:https://arxiv.org/abs/2005.14165。
このことは、楽に転移学習に使えること、とも関係しています。GPT-3は事前学習したモデルと同じモデルを転移学習に使用できます。つまり、モデル再構築やアルゴリズムの最適化のプロセスを省くことができ、少量の正答例を付与するだけで、文章生成など個別のタスクにモデルを適用します。ただし、事前学習(基礎訓練)には相変わらず膨大な量のデータが必要であることに注意してください。
GPT-3は、驚くほど高度なタスクを実行できる能力を示している一方で、その利用に関しては社会的な問題とリソース的な問題が報告されています。後続の記事では、このようなGPT-3の活用に関する課題について述べます。 ここまで読んでいただきありがとうございました。それでは、次回またお会いしましょう。
記事担当:ヤン・ジャクリン(分析官・講師)
関連記事
【5分講義・自然言語処理#3】事前学習と転移学習・そしてBERTも
本記事ではまず「事前学習モデル」を紹介し、自然言語処理における代表的な手法の1つであるBERTを詳しく解説していきます。後続の記事では最新のGPT-nモデルについても紹介していきます。
■まず、事前学習とは
ディープラーニングにおける事前学習モデル(pre-trained models)とは、大規模なデータセットを用いて訓練した学習済みモデルのことです。一般的に、特定の分野(例:画像分類、テキスト予測)のタスクに共通な汎用的な特徴量を隠れ層にて「習得」してあるため、転移学習(transfer learning)に利用することができます。事前学習及び転移学習をセットで活用することで、手元にある学習データが小規模でも高精度な認識性能を達成することが出来ます。 転移学習を画像認識の文脈でよく聞きます。例えば、VGG16やResNetなどはImageNetなどを用いて事前学習した画像認識モデルです。同じ仕組みが自然言語処理にも応用されています。同様に、巨大なテキストデータ(コーパスと呼ぶ)を用いて、汎用的な特徴をあらかじめ学習しておきます。 従来では、比較的小さ目のデータセットを使って、翻訳や質問応答などに特化したモデルを学習するのが主流でした。2018年以降、巨大コーパスで言語モデルの事前学習を行ったモデルを転移学習に用いる手法に成功しました。それをきっかけに、BERTやGPT系モデルなど、転移学習に使いやすい事前学習モデルが次々と開発・改良されています。
■BERTとは
事前学習された言語モデルの先行者は、2018年にGoogleによって提案されたBERT(Bidirectional Encoder Representations from Transformers)です。
(原論文)[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERTの名称にある"Bidirectional Encoder"はどういう意味でしょうか?
わずかに話を逸らして詳細を説明します。リカレントニューラルネットワーク(RNN)を積み重ねて使用することができます。1つのRNNからの出力を別のRNNに入力するだけです。ところが、単独のRNNは過去から未来へと一方的にしか学習できません。そこで、「過去用」と「未来用」の2つのRNNを組みわせると双方向の情報を学習に活用できるようになります。
この双方向言語モデルのコンセプトはBERTにも採用されています。少し違うのは、RNNの代わりにエンコーダにTransformer を使っている"Bidirectional Transformerモデル"であることです。Transformer自身は、エンコーダとデコーダにAttentionのみを採用しており、学習の高速化や離れた位置にある単語同士の関係性も捉えやすいなど様々なメリットがあります。
いずれにしても、BERTでは「過去から現在」と「未来から現在」の双方向(Bidirectional)の情報を同時に使用できることがここでのポイントです。BERT は開発当時から各種の自然言語処理タスクで精度スコアの記録を更新し続け、その高い性能と汎用性に一気に注目が集まりました。下図(出典:2018年10月11日にGoogleからArxiv公開された論文)のように、転移学習に使用すると、8個のベンチマークタスクでSOTAを達成しました。

ちなみに、機械翻訳など言語モデルのベースとなるエンコーダ・デコーダモデルについては以下を参考にしてください。 gri-blog.hatenablog.com
■BERTの学習法と使い方
BERT の学習は、次の2段階から成り立ちます。
事前学習:大量のデータを用いる
ファインチューニング:比較的少量のデータを用いて新しいタスクに適用する
そのうち、BERTの事前学習は、以下の2種のタスクを巨大なコーパスを用いて行います。
- Masked Language Model (MLM;空欄語予測) * Next Sentence Prediction(NSP;隣接文予測)
MLMでは文章をトークンに分けた後に、一部(~15%)を「マスク」して隠した状態で入力し、マスクされた箇所のオリジナルの入力単語をモデルに予測させます。NSPでは2つの文を結合した状態で入力し、2つの文が連続する文かどうかのT/Fを予測させます。ここでは入力文章の合計系列長が512以下になるように2つの文章 をサンプリングしています。 BERTの訓練データには、BooksCorpus(800MB)と English Wikipedia(2500MB)を使用します。
■BERTのモデルがどんなに大きいのか
2018年に提案されたBERTのパラメーター数は3億程度でした。計算コストを下げるために、パラメータ数を削減する工夫を施されました。2019年に、BERTの軽量版であるALBERTやDistilBERTが公開されました。実は、BERTのサイズは次回紹介するGPT-2, GPT-3に比べてはまだ比較的抑えられている方です。
他に、ロジックはBERTを参考にしている、MT-DNN(Multi-task deep Neural Networks)がMicrosoft社から発表されています。その性能はBERTを上回っていると言われています。
記事担当:ヤン・ジャクリン(分析官・講師)
生成モデル「GAN」を簡単に紹介(夏季インターンシップ募集中)
こんにちは!弊社は現在学生向けのインターンシップを募集してます。内容は最新の AI 技術を使って開発を行ってみよう!!といったものです。8/15 まで募集していますので学生の皆さまは奮って参加をお願いします!
今回は、このインターンのテーマの一つである GAN (Generative Adversarial Networks: 敵対的生成ネットワーク)についてザックリ紹介します。
GAN でできること
GAN は主に画像生成で有名になった生成モデルです。生成モデルは GAN の他にエンコーダーとデコーダーを並べて変分ベイズ法によって誤差逆伝搬を可能にした VAE モデルがあります。しかし、VAE は損失に正則化項を加えたことにより、生成した画像がぼやけてしまうという欠点があります。一方で、GAN はシャープな画像が生成され、ディープラーニング界にブレイクスルーをもたらしました。 そこから色々な派生が生まれて、ただ画像を生成するだけではなく、高解像度化・ドメイン変換・異常検知・画像再構築など多くのタスクをこなしてきました。例は以下の github になります。
GAN がやっていること
GAN には生成器(Generator)と識別器(Discriminator)と呼ばれる二種類のモデルがあり、これらの二つのモデルが切磋琢磨しながら学習することで最終的に良質なデータを生み出す生成モデルになります。
Generator

Discriminator

学習
Generator の学習

Discriminator の学習

収束条件
一般的なディープラーニングでは損失が最小になるように最適化を行うため損失値が収束条件になったりしますが、 GAN では Discriminator の損失を Generator の学習では最大化するように、 Discriminator の学習では最小化するために学習を行うため収束条件としては使えません。では、どうなれば収束となるかというと、次の二つが挙げられます。
- どのデータを入れても Discriminator が「本物」と判定する確率が 0.5 である
- Generator が生成したデータが確かに学習に似ている
同じようなことを言っているように見えますが、上の条件だけでは学習の途中である可能性があるので生成されたデータをしっかり見ることが大事です。
そして、この状態になるまでには Discriminator の損失が振動する必要があります。この振動が起こっているときには Generator が Discriminator を騙すのに成功し、それを受けて Discriminator が Generator に騙されないようになることが繰り返されているので両モデルが成長している状態であるといえます。この関係が崩れてどちらかのモデルが強すぎてしまうと、学習が上手くいかなくなります(勾配消失やモード崩壊と言います)。このモデルの調整が難しく、この問題を解消するために色々な工夫がなされています(LSGAN, WGAN, α-GAN, etc...)。
というわけで GAN の紹介でした。インターンのテーマは GAN に限らず他にも興味深いものもありますし、テーマの持ち込みも可ですので興味がある方は是非参加してみて下さい!
分析官 安井優平
puppeteerを使ってJavascriptなサイトをクロールする
インストール
早速実践していきます
まずはインストール...
yarn add puppeteer # or "npm i puppeteer"
インストールが完了すればnode_modulesフォルダの中に色々入ります
$ npm install pic.twitter.com/RQdSqcGXHT
— Zeno Rocha (@zenorocha) June 25, 2021
これでOKです
チュートリアル
githubのexampleをさらいます
// example.js const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://example.com'); await page.screenshot({ path: 'example.png' }); await browser.close(); })();
実行
続きを読む