イケてるスパゲッティチャートの作り方②
こんにちは!分析官の望月です。
前回の記事でイケてるスパゲッティチャートの作り方を紹介しました。
イケてるスパゲッティチャートの作り方① - GRI Blog
本記事では前回作成したチャート(下図)にもう少し改良を加えることでより見やすいスパゲッティチャートを作成していきます。

改良点1:選択したサブカテゴリをより際立たせる
選択したサブカテゴリをより際立たせるために選択外サブカテゴリの折れ線を細くします。
手順は以下の通りです。
- 選択されたサブカテゴリのみ売上集計される計算式[sales_sc]を作成

- 行に[sales_sc]の合計を入れて二重軸にする

- [sales]と[sales_sc]の軸を同期させる

- マーク→合計(Sales)→サイズから折れ線のサイズを調整

- シート右下のインジケータを非表示にする
改良点2:ツールヒントの整備
選択したサブカテゴリのみツールヒントが表示されるような仕様にします。
手順は以下の通りです。
- マーク→合計(Sales)→ツールヒントからテキストを削除

まとめ
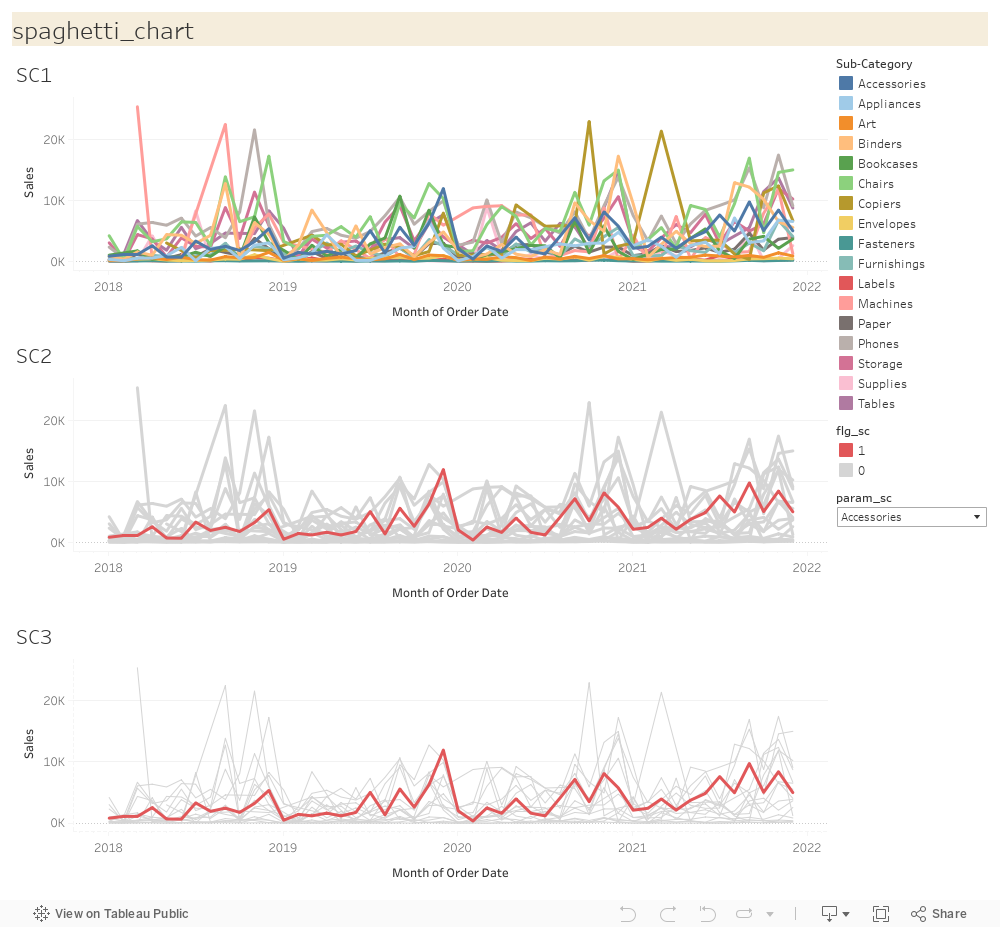
ダッシュボード最下部のチャートが上記改良を施したスパゲッティチャートです。
改良前のチャートと比べてみると、どのサブカテゴリに着目すべきかが明らかになっており、知見を得やすくなっています。
このようにスパゲッティチャートは絶対悪というわけではなく、表現方法によって有効な表現方法にもなり得ます。
是非ためしてみてください!
イケてるスパゲッティチャートの作り方①
こんにちは!分析官の望月です。
みなさんはスパゲッティチャートをご存じでしょうか?
スパゲッティチャートは下図のように同一シート上に折れ線グラフがいくつも重なっているチャートであり、
見た目がスパゲッティのように見えることからそのような名称で呼ばれています。

上図を見れば一目瞭然だと思いますが、 一般的なスパゲッティチャートは情報量が多すぎることで知見が得づらくなるため、可視化の現場では避けられがちです。
しかし、表現方法を少し変えることでスパゲッティチャートも十分有効なグラフになり得ます。 本記事ではTableauを用いたイケてるスパゲッティチャートの作り方を共有します。
使用するデータ
Tableauユーザーにとっては毎度おなじみ、スーパーストアのデータを使用します。
一般的なスパゲッティチャートの作り方
今回はサブカテゴリごとの売上推移をスパゲッティチャートで表現してみます。
作成手順は以下の通りです。
- 列に[order_date], 行に[sales]の合計を入れる
- マークの色に[sub_category]を入れる

イケてるスパゲッティチャートの作り方
一般的なスパゲッティチャートは色を使いすぎており、それが情報量過多の主な要因になっています。
そこで選択したサブカテゴリは目立つ色、それ以外は目立たない色となるようにして1つのサブカテゴリにフォーカスを充てたスパゲッティチャートを作成してみます。
作成手順は以下の通りです。
- 列に[order_date], 行に[sales]の合計を入れる
- サブカテゴリ選択用のパラメータ[param_sc]を作成

- 配色を制御する計算式[flg_sc]を作成

- マークの詳細に[sub_category], 色に[flg_sc]を入れる
- 色→色の編集から好みの色に変更

- [flg_sc]==1がシート前面にプロットされるよう、[flg_sc]を並べ替える

下図が修正後のスパゲッティチャートです。
この表現方法だと、選択したサブカテゴリの売上推移とともにざっくりではありますが他のサブカテゴリとの比較も行うことができます。
修正前と比べるとだいぶスッキリしましたが、次回の記事ではもう少し改良を加えることでより見やすいスパゲッティチャートを作成していきます。
乞うご期待!
Grad-CAMで画像認識を可視化(Part2)
前回のPart1の記事では、機械学習モデルの解釈性の重要性、そしてGrad-CAMを中心とする、いくつかの予測根拠の可視化ツールを紹介しました。
今回は、早速Grad-CAMを実装してみましょう。
環境・設定:
Google Colaboratory 上でJupyter Notebook を走らせる
ディープラーニングのライブラリとしてKerasを使用
ResNet50を転移学習に使用
入力画像:図1

図1:入力画像
Grad-CAMを実装するコード

まずimport の部分では、Kerasから必要なモジュールを持ってきます。そして今回はResNet50を使用します。

GradCam というクラスを作成します。このクラスの中で、まずモデルの初期化を行い、続けてGrad-CAMの実質的な内容を定義する関数を構築します。
初期化 def init の部分では、最後の畳み込み層の名前を確認するために、各レイヤーの名称の情報のprintをさせています。
その下の def gradcam_func(...) はGrad-CAMの実際の機能を実装する関数です。まず入力画像のピクセル数値のデータ型を調整し、正規化を行います。
このmainの部分で行う処理は概ね以下となります。
入力画像の読み込み・前処理
画像認識用のモデルの読み込み
入力画像のクラス(確率)を予測する
Grad-Camの計算(勾配を計算し、それをRelu関数に通した値をヒートマップの値にする)
出力画像の保存

この部分では、畳み込み層の最後のレイヤーを受け取り、モデルに渡します。
勾配を記録するためのメソッドとして tf.GradientTapeがあります。勾配を計算するために、numpy配列をtfの型に変換します。 続いて、予測したクラス及びそのクラスの特徴量を取得します。
次に、上記で得られた情報を使って勾配を計算します。

勾配を記録するために tf.GradientTape() の中のgradient() 関数を用いて勾配を計算したのちに、Global Average Pooling (GAP)を実装して平均を取ります。最後に、ヒートマップの値を計算するために勾配値をRelu 関数に通す必要があります。ReLU関数からの出力された値がヒートマップの値となります。
また、以前入力データの前処理で正規化をしていたので、ここで正規化前の値に戻します。クラスの最後の部分はcv2の関数を使ってカラーのマップを作ります。
以上で、メインの関数の定義が終わりました。ここからは、クラスGradCamをメインコードで呼び出して、実際に画像を入力して、予測結果の解釈を行ってみましょう。

まずmodelを呼び出します。重みはimagenetで訓練したものです。画像をgoogle drive から読み込むときにちょっと一癖があります。本記事の一番最後の画像をマウントするための一例を載せますので、ご参考にしてください。グーグルドライブ上で「マイドライブ」として見えているものは、ディレクトリー構造でいうと、/content/dive/My Drive/ のであることが多いです。出力の場所も同様に設定します。
読み込んだ画像をリサイズし、gradcam関数を呼び出します。コードの実行が終われば、out.jpgという解釈結果のヒートマップがマイドライブに出来上がっているはずです。これをみてみましょう。
ここまでのコードを実装します。

得られたアウトプット画像は以下のようです。ご覧のように色分けで画像分類の際の注目度を表示しています。

参考:Gドライブへ画像をマウントする方法
複数のやり方があります。ここでは単なる一例です。
いかがでしたか、転移学習やKerasの便利な機能を使えるため、コード自体は難しくなりません。ぜひご自身が試したい画像で画像認識解釈のヒートマップを出力してみてください。
今回も読んでいただき、ありがとうございました。次回もお会いしましょう。
記事担当:ヤン ジャクリン(分析官・講師)
Grad-CAMで画像認識を可視化(Part1)
ディープラーニングは数多くある機械学習の手法の中でも、特に画像・音声・文章などの非構造化データに対する識別能力を発揮します。
参考記事:
しかし、ディープラーニングの課題の1つは、モデルによる判断の根拠が解釈しにくいことです。この性質はよく「ブラックボックス性」と呼び、がディープラーニングの活用を難しくしていると思われます。
本記事シリーズでは、機械学習モデルの解釈可能性を高めるためのツールを紹介します。
そもそもなぜモデルの「解釈性」が重要だと思いますか?
「なぜ予測が当たっているのか」を明白に説明できていないと、モデルを実社会に実装した際に、そのアプリケーションの利用者が不安を感じさせてしまいます。
ここで以下のシナリオを想像してみてください。
医者から「AIによる医療診断の結果、腫瘍は悪性ですが、AIがそう判断した根拠は解明できません」と言われました。患者は一体どんな気持ちになるのか ....
逆に機械学習を用いて病気の有無を判断するだけではなく、病気を悪化させている要因を特定できれば、より早めに医療処置で対処できるようになります。
上記のような極端に高リスクのシナリオでなくても、機械学習による判断根拠の解釈が重要となる場面は実にいろいろ考えられます。例えば、大学側が奨学金の審査を機械学習モデルを立てて判断しようとする際に、万が一ある方の奨学金申請を拒否した場合、法律上その判断の根拠を説明する必要があります。
脱ブラックボックス性のためのツール
そこで、近頃機械学習モデルの解釈性に注目し、ブラックボックス性の解消を目指した研究が進められています。以下は、モデルの解釈に使われる代表的なツールとして挙げられます。
* LIMEとSHAP:モデル全体の傾向ではなく、特定のデータサンプルに着目し、単純なモデルで近似することで予測に寄与する因子を推定する 「局所的な説明ツール」
- Grad-CAM: 勾配情報を活用することで、ディープラーニングモデルそのものに判断根拠を持たせる
その他にも機械学習の解釈をサポートする機能が開発されています。ランダムフォレストのfeature importanceやpartial dependenceは特徴量の重要度を可視化し、Attentionはニューラルネットワークにおける時刻ごとの情報の重みを考慮する機構です。
以下では、モデル全体の解釈を進ませるGrad-CAMについて説明していきます。本シリーズのPart2ではGrad-CAMの実装をデモンストレーションします。
Grad-CAMとは
上記で触れたLIMEとSHAPは個別のデータサンプルに対して、その結果を別の単純なモデルで近似していくアプローチでした。これに対して、Grad-CAMは、CNNベースの画像認識モデルを対象としており、モデルそのものに判断根拠を持たせる手法であることがポイントです。具体的に、「画像のどこに注目してクラス予測をしているのか」を解析・可視化します。
Grad-CAMでは、CNNが分類のために注目していると推定される範囲を、ヒートーマップで表示します。図1の中央がGrad-CAMを適用し可視化している例です。これによって、画像のどの部分を見て猫を予測しているのか、そして、モデルは正しく猫を認識していることを目視で確認できます。
もう少し詳しく説明すると、Grad-CAMの名前には”Gradient” = 「勾配」という意味が込められています。実は、モデルの学習に用いられるのと同じ勾配の情報を可視化にも使っています。勾配が大きいピクセルは全画像のうちクラスの予測出力に大きく影響する場所である、というのが発想です。より重要と思われるピクセルにはより大きな重みをつけて、このように計算した重みを可視化用のヒートマップの計算に反映させます。ちなみに、CNNには畳み込み層が数多くあり、Grad-CAMで使われるのは、最後の畳み込み層の予測クラスの出力値に対する勾配値です。
Grad-CAMの課題と改善点
一般的なGrad-CAMの問題点は、解釈過程の中で画像の解像度が下がってしまうことです。この問題点を解決するために、入力値における勾配情報も合わせて使う Guided Grad-CAMという改善版が開発されています 。Guided Grad-CAMは、分類モデルが着目している場所をさらに詳細に可視化してくれます。図1の一番右はGuided Grad-CAMを用いた解釈結果であり、ここでは具体的に猫のどういう特徴を抽出しているのかまで可視化することが可能になっています。

(左)元画像(中央)Grad-CAMによるアウトプットで分類において注目している猫の特徴をヒートマップで表示(右)Guided Grad-CAMによるアウトプットで、注目されている猫の特徴が更に際立つ
画像引用元:https://github.com/vense/keras-grad-cam
ここまで読んでいただき、ありがとうございました。後続記事のPart2では、Grad-CAMを実際実装した例をデモンストレーションしたいと思います。それでは次回またお会いしましょう。
記事担当:ヤン ジャクリン(分析官・講師)
【5分講義・深層強化学習#2】DQN手法を用いたAlphaGOその後の進化
以前の記事では、深層強化学習、そしてその代表的な手法であるDQNについて紹介しました。
深層強化学習以前のゲームAIは、以下を使ったものが主流でした。
深層強化学習が実用化に伴い、ディープラーニングを従来の探索木手法や画像認識技術と組み合わせることが可能になりました。強化学習の応用の幅を広げています。DQNは、Atariゲームやその後に囲碁AIででも著しい成果を残しています。 DQNを活用したデビュー実績は、2013年にAtari社のブロック崩しゲームで人間のスコアを超え、反響を引き起こしたことです。その後は囲碁AIにおいても継続的に成果を出しています。そして今では、DQNをはじめとする深層強化学習の手法は、難易度の高いゲーム以外に、自動運転、ロボティクスにも活用されはじめています。
囲碁AIのAlphaGo
深層強化学習(DQN)の囲碁AIにおける最初の大きな実績は、2015年に世界トップの棋士(イ・セドル九段)を打ち倒したAlphaGo(アルファ碁)です。AlphaGoはDeepMind社によって開発されました。打つ手の探索にモンテカルロ木探索法を使用し、碁盤の状況認識にCNNを使用します。盤面情報を符号化したデータを入力として勝率を計算します。人間がプレイした棋譜データを学習データに使用し、教師あり学習を行っています。
アルゴリズムの改善を経て、 2017年10月に、AlphaGoの強化版AlphaGo Zero(アルファ碁ゼロ)が同じくDeepMindから発表されました。AlphaGo Zeroの最大の特徴は、完全自己対局(self-play)で学習していることです。つまり、過去の棋譜を学習することなく、最初から自分自身と戦うことで得られたデータのみ使って深層強化学習を行います。初期状態ではランダムな動きしかとれないけど、場数を踏んでいくうちに「勝てる行動パターン」を習得し、どんどん「賢く」なっていきます。
完全自己対局が可能になったことがAIの研究分野に大きなインパクトを与えました。なぜなら、伝統的な知識の蓄積やそのバイアスに依存することなく、完全にゼロベースから学習を進めた方が良い場合もある、ということを思い知らせられたからです。
AlphaGo Zeroは、AlphaGoで必要だった教師データが必要でなくなり、それでいてAlphaGoよりも強くなれました!
自己対戦のみで学習できるもう1つのAlphaGoの発展版として、Alpha Zero(アルファ・ゼロ)もあります。こちらは 、囲碁に限らず、将棋やチェスなどの分野でも、過去に開発された人間を超えるゲームAIに勝てる性能を示しています。だから名前に「囲碁」の「Go」がつかないわけですね。
さらに、2019年にAlpha Star(アルファ・スター)が開発されました。名前の由来は、「スタークラフト」というゲームにおいてトップマスターを打倒できたことから来ています。Alpha Starは、ResNet、LSTM、トランスフォーマーなど、本体は画像認識や自然言語処理のためだった手法を組み合わせて学習を行います。
ここまで読んでいただきありがとうございました。それでは、次回またお会いしましょう。
記事担当:ヤン・ジャクリン(分析官・講師)
(追記)後続の記事では、DQNについてずっと後に開発され、計算の効率も性能も従来のアルゴリズムに優れるA3Cという深層強化学習のアルゴリズムについて書いています。
【5分講義・深層強化学習#1】深層強化学習そしてDQN手法、何が強いのか
この記事では、従来の強化学習の延長上に研究が進められてきた深層強化学習について、従来の強化学習に対する改善点、技術の進化、課題などを述べていきます。
まず、「強化学習」についてはじめて学ぶ方のために、簡単に一言説明:
試行錯誤や探索を通じて、意思決定と行動最適化のルール、つまり「最終的に環境から最大の報酬をもらうために、どんな行動をとるべきか」を学習することが目的である
深層強化学習のはじまり
強化学習の研究は1990年代を中心に栄えていました。しかし、以下の難点にぶつかっていました。
「状態」の表現の仕方が難しい
状態に対して、現実的な時間内で行動を判断することが難しい
実世界での応用が困難と思われたため、強化学習の人気は、2000年代に一時期衰退してしまいました。
従来の強化学習では行動の組み合わせの全パターンを計算していたため、現実的な速度で課題に対応できないのが問題でした。このに対応すべく、深層強化学習が開発されました。深層強化学習は、ディープラーニングと強化学習を組み合わせた技術です。ディープラーニングを用いることによって、学習にとって本質的な部分を見つけ出しやすくなりました。そうすると、状態や行動の表現が改善され、強化学習の使い道がグッと広げられました。
代表的な手法は DQN(Deep Q-Network)
深層強化学習の圧倒的に代表的な手法は DeepMind社が開発したDQN(Deep Q-Network)です。DQNは、従来の強化学習モデルにおけるQ学習を基本的な思想としており、その上にCNNを取り入れています。
強化学習の学習法の基本: Q学習
DNQやQ学習には、Q値(状態行動価値)という用語が深く関連します。Q値とは、各状態においてエージェントがある行動を実行することで得られる報酬の期待値と解釈することができます。1つの状態と行動の組み合わせに対して1つのQ値が割り当てられます。新しい状態に遷移し別の行動を選択するたびにQ値が更新されます。Q学習というのは、Q値を最大にするように学習を行う手法です。
従来の強化学習では、「状態」を表現することや、状態の1つ1つに価値関数(Q値)を割り当てることが困難でした。例えば、囲碁を対戦するAIの場合、状態が碁盤の画像として与え、画像のピクセル値がわずかに変動しても別の状態と認識されてしまいます。ロボット制御などの複雑なタスクでは状態の組み合わせが膨大に膨らんでします。これに対して、深層強化学習は、行動価値や方策を推定するアプローチをディープラーニングに置き換え、状態を「そのままの形」(例:碁盤の画像)でCNNに入力することができます。DQNでは、状態と行動と報酬をまとめた「Qテーブル」に対し、ディープラーニングで回帰を施し、これを近似することで状態数が膨大になっても学習の時間が発散せずに済みます。
一般的にディープラーニングを含む機械学習では、サンプル間の相関は学習結果に悪影響を及ぼします。DQNの初期には、エージェントから得られるサンプル同士に強い相関があることが問題視されました。これへの解決策は、Experience Replay(経験再生)というテクニックです。サンプルのバッファーから一度に複数のサンプルを取り出してミニバッチ学習を行うという仕組みです。これによって, サンプル間の相関を軽減でき、DQNを上手くいくようになりました。
DQNの有名な活用事例
DQNのデビュー実績は、2013年にAtari社のブロック崩しゲームで人間のスコアを超え、反響を引き起こしたことです。その後2015-17年にDeepMind社開発の AlphaGo(アルファ碁)シリーズのモデルが世界トップの棋士を次々の打ち倒しました。その後、DQNをベースに多くの深層強化学習の改良版モデルが開発され、深層強化学習は今では難しいゲーム以外に、自動運転、ロボティクスにも活用されはじめています。
深層強化学習の技術の進歩
経験再生やネットワークの構造などを工夫することで、これまでに、DQNを拡張させた深層強化学習の手法が数多く開発されました。有名なものとして、ダブルDQN(Double DQN; DDQN)、デュエリングネットワーク(Dueling Network)、ノイジーネットワーク(Noisy Network)などが挙げられます。これらのアルゴリズムの良い特徴を組み合わせた「全部載せ」モデルが RAINBOWです。図1にあるように、Atariゲームを用いた試験においては、RAINBOWは他の全ての手法に勝るパフォーマンスを示しました。

次の記事では、DQNの活用事例、特に、AlphaGOシリーズのアルゴリズムの進化について述べていきたいと思います。
ここまで読んでいただきありがとうございました。それでは、次回またお会いしましょう。
記事担当:ヤン・ジャクリン(分析官・講師)
(追記)後続の記事では、DQNについてずっと後に開発され、計算の効率も性能も従来のアルゴリズムに優れるA3Cという深層強化学習のアルゴリズムについて書いています。
【5分講義・深層強化学習#4】A3Cの手法の中身と性能を理解
以前の記事ではA3Cアルゴリズムを紹介しました。エージェントの非同期な学習を特徴とし、学習の高速化と安定かの効果があります。
今回この記事では、A3Cの学習法をさらに詳しく解説し、他の深層強化学習の手法と比べた性能をお伝えします。イメージとしてはA3Cの仕組みの全体像を把握し、原論文にも挑戦できるようになることです。 原論文:https://arxiv.org/pdf/1602.01783
A3Cの学習の仕組み
A3Cは分散型のActor-Criticネットワーク構造をしています。以下の2点を理解すればよいです。 * 一般的なActor-Criticでは、方策ネットワークと価値ネットワークを別々に定義し、別々のロス関数(方策勾配ロス/価値ロス)でネットワークを更新します。 * A3Cはパラメータ共有型のActor-Criticを持っています。1つの分岐型のネットワークが方策と価値の両方を出力し、たった1つの「トータルロス関数」でネットワークを更新します。
A3Cの学習に用いられるロス関数は3項目で表せます:アドバンテージ方策勾配、価値関数ロス、方策エントロピー
Total loss =− アドバンテージ方策勾配 +α・価値関数ロス −β・方策エントロピー
ここで、係数αとβはハイパーパラメータです。特に係数βは探索の度合いを調整するハイパーパラメータです。
一般的に、方策勾配法では、 θ をパラメータに持つ方策 πθ に従ったときの期待収益 ρθ が最大になるように、 θ を勾配法で最適化します。方策勾配定理により、パラメータの更新に用いられる勾配 ∇θ ρθ は、以下の式で表されます。

(式1)の中の Qπθ (s, a) − b(s) にアドバンテージ関数を設定します。A3Cの特徴としては、勾配を推定する際に、b(s)の推定には価値関数V πθ (s)、Q(s,a)の指定には、kステップ先読みした収益を用いることです(下式)。
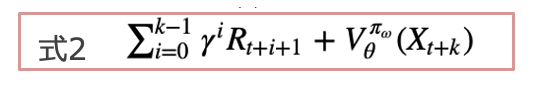
つまり、下記(式3)の期待値が(式1)の勾配と等価です。

ちなみに、A3Cの方策エントロピー項からは、方策関数の正則化効果が期待できます。方策のランダム性の高い(=エントロピーが大きい)方策にボーナスを与えることで、方策の収束が早すぎて局所解に停滞する事態を防ぐ効果があることが知られています。
A3Cの性能
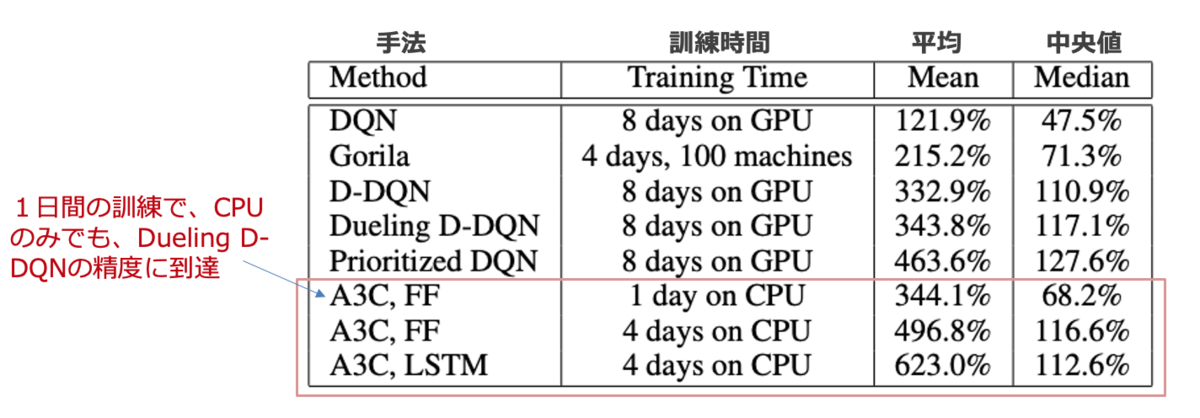
ここでは、A3cの性能検証の結果を原論文から引用します。
下図は、ゲームAtari 2600において、人間のスコアに対して規格化した深層強化学習モデルの結果です。A3Cは、16 CPUコアのみ使用、GPUを使用していないことに着目してください。また、訓練時間も1~4日間で、それまでの他の代表的なモデルより短いことが分かりますね。他のエージェントはNvidia K40 GPUを使用しており、ほとんどは8~10日間の訓練を要しています。結論をいうと、A3Cはより短い訓練時間でGPUを使わなくても、顕著に高いスコアを達成することができます。
A3Cの実装に挑戦したい方は、以下が参考になります(TensorFlow Blogより)。 https://blog.tensorflow.org/2018/07/deep-reinforcement-learning-keras-eager-execution.html
ここまで読んでいただきありがとうございました。それでは、次回またお会いしましょう。
記事担当:ヤン・ジャクリン(分析官・講師)