GASをいじっていて、ちょっと躓いた話
こんにちは!
分析官のMです。
最近、
「spreadsheetに記入したデータをGoogle Apps Script(GAS)を用いてGoogle Cloud Storage(GCS)に格納する」
仕組みを作っていたのですが、思わぬところで時間をとられてしまいました。
本記事では私がどこで躓いてしまったかを備忘録的にまとめています。
興味がある方は是非覗いてみてください。
結論から言うと...
「V8ランタイム対応前に作成されたライブラリはV8ランタイムに対応していない可能性があるので使用する際は注意が必要」
ということです。
実際に私がどのようなスクリプトを書いてどこで躓いたのか、もう少し具体的に説明します。
スクリプトの構成
スクリプトの構成は以下のような感じです。
Step-1 spreadsheetからGCSに転送したいデータを配列形式で取得
Step-2 配列形式から","区切りのテキストに変換
Step-3 一般公開されているライブラリを用いて認証(https://github.com/Spencer-Easton/Apps-Script-GSApp-Library)
Step-4 適当にファイル名(**.csv)をつけてGCSに格納
躓いた点
恥ずかしながら私はStep-3で躓いてました...。
ライブラリの使用例と比較しても同様のコードになっているのになぜかエラーの嵐。
https://github.com/Spencer-Easton/Apps-Script-GSApp-Library/blob/master/example.gs
色々ググっているうちに以下の記事にたどり着きます。
https://auto-worker.com/blog/?p=691
記事の内容は
「GASは2020年2月にV8ランタイム対応になって便利になったけど、いきなりバージョンアップするのは結構危険やで。」
といった内容。
ほうほう。
さらに読み進めてみると、
「V8ランタイムに対応していないライブラリはV8ランタイムではエラーになるで。」
というような文章が...。
自分:「あー、これが原因ぽいな...」
はい、その通りでした。
実際にGASの設定画面で
"Chrome V8ランタイムを有効にする"のチェックを外して再実行してみると、無事GCSにcsvファイルが格納されました。
とりあえず一件落着。
おまけ
GASをざっくり理解するには以下の動画がおすすめです!
https://www.youtube.com/watch?v=_fOfwvKm9zU
Airbyteを試してみた
Open SourceのETL(今のところExtract Transform LoadのうちExtractとLoadメインみたい)ツール、Airbyteを試してみました。TechCrunchでは、オープンソースのデータパイプラインプラットフォームとして紹介されていました。
用意されているSourceとDestinationを組み合わせて、スケジュールを実行の設定ができます。差分更新ができるコネクターが限られていたりはしますが、シンプルに散在しているデータをBigQueryってときとかは使えるかもしれません。
続きを読むTableauのLOD FIXEDは、SQLのWindow関数と同じか
TableauのFIXEDで、初歩的なところでハマったので共有します。
- FIXEDで集計したものをIIF文に入れて平均したものと、
- FIXEDの中身の時点でIIF文で条件を入れて平均したもの
は結果が変わります、という話になります。ちなみに私が元々やりたかったのは、後者でした。例えば、SuperStoreのサンプルデータで、顧客ごとの売上の平均を出したい。ただし、ロサンゼルスの顧客だけで集計したいみたいなときです。
続きを読むホワイトボードアプリGoogle Jamboardを試してみた
ホワイトボードアプリGoogle Jamboardが気になったので、少し試してみました。
続きを読む機械学習モデルの解釈の入門: Partial Dependence Plot(部分依存グラフ)
背景
ビジネスかアカデミアかに関わらず、機械学習モデルを扱う際には、モデルの解釈が必要になることが多いです。今回は、機械学習モデルを解釈する手法の一つ、Partial Dependence Plotを紹介いたします。
※以下、Partial DependenceをPDと略します。
PDPlotのイメージ
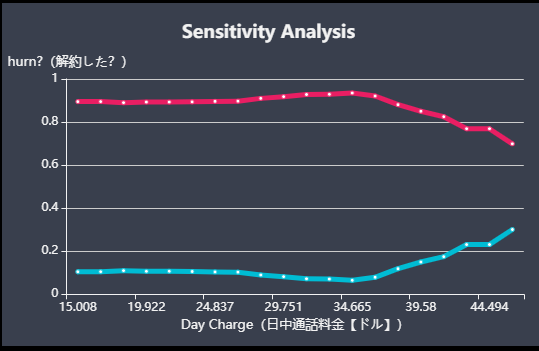
上の画像がPDPlotのイメージです(青線に着目してください。横軸:日中通話料金、縦軸:機械学習が予測した解約しやすさを表すスコア)。
これは、電話会社の顧客が次月契約を継続するかを予測するモデルにおける、日中通話料金という特徴量についてのPDPlotです。
PDPlotは、モデルにおける目的変数の対象特徴量への依存の仕方を表します。この例では、35ドル付近の時最も解約しにくく、50ドル付近が最も解約しやすい、ということを表しています。
これを定義から整理して正しく理解することが本記事の目的です。トップダウンに見ていくと見通しが良いので、本記事は以下の構成としました。
- PDPlotの定義、仮定、計算方法
- PDPlotの性質
- PDPlotについてのまとめ
内容が繰り返しになってしまっている部分がありますが、数式を読むリテラシーにかなり幅があるので、丁寧に記述した結果そうなってしまっています。ご了承ください。
PD関数 の定義、仮定、計算方法
の定義、仮定、計算方法
ここでは雰囲気だけ見ていただければ、定義の意味がよく分からなくても大丈夫です。
定義
式で使われている文字の意味
: PDPlotを描く対象となる、1つか2つの特徴量、またはその値
: モデルの他の特徴量、またはその値(
と
の組み合わせで、特徴量全体となる)
] : 特徴量
の分布における変数
の期待値
: 機械学習モデル
仮定
と
が独立
計算方法
式で使われている文字の意味
: 訓練データの件数
:
番目のデータの特徴量
の実際の値
PDPlotの性質
以下の記述のおおよそは、定義を観察しなければ理解できないので、定義に立ち返りつつ読んでいただければと思います。
定義の基本的なポイント
PDPlotを定義から一言で読み解けば、
- 対象特徴量の予測スコアへの(Globalな)平均限界効果を表す
- 平均限界効果の算出の仕方は、「他特徴量の分布を、対象特徴量の分布と独立に考えて確率平均を取ること」で見積もっている
ということだと思います。
「限界」は、日常的な意味で使われる「ギリギリの境」という意味ではありません。「限界」は「対象とする変数の変化だけ考慮したときの」という経済学的な意味です。例えば、限界利益(=固定費を度外視して変動費だけ考慮した利益)もこの経済的な意味で「限界」という言葉が使われています。
PDPlotの話に戻ると、もともと機械学習モデルは「全特徴量の値」→ 予測スコアという関数ですが、PDPlotは「対象特徴量の値」→ 平均予測スコアという関数になっていて、「対象特徴量の変化だけを考慮したときの」という意味で「限界」となっていることを確認できます。
その上で、Globalな(=全サンプルを考慮した上での)平均限界効果を算出する方法、つまり、モデルの引数から(全サンプルを考慮した上で)他特徴量の値を除く方法は、様々あり得ます。繰り返しになりますが、PDPlotでの方法は、他特徴量の分布を、対象特徴量の分布と独立に考えて確率平均を取るという方法です。(これは、の値を人為的に固定し、その値がどんな値かに関わらず、実データの
の分布のみに応じた確率平均を算出しているということです。)「独立に考えて」の部分を正当化するためには、対象特徴量がその他の特徴量と独立である必要があります(これゆえに、「
と
が独立」という仮定をしています)。
この定義は、定義を見れば分かりますが、Globalな平均限界効果を考える上で最も単純な定義になっていると思います。
強みと弱み
上記「定義の基本的なポイント」を理解すれば自明ですが、強みと弱みについてまとめました。
強み
- モデルにおけるGlobalな目的変数の対象特徴量への依存性を、特徴量と目的変数の因果関係として定量的に見積もっていること
- 専門家でない人にとっても直観的に分かりやすいこと
このような強みは、「定義の基本的なポイント」を理解すれば分かることなので省略いたします。
弱み
と
に相関があると、PDPlotの値はおかしくなること
- 対象の特徴量
2点目についてです。繰り返しになりますが、PDPlotは、対象特徴量の目的変数への限界効果を表します。つまり、
と
の組み合わせで目的変数へどう効くか(=交互作用)という情報はなくなっているということです。ただし、2つの特徴量の交互作用は、
として2つの特徴量を選ぶことで見られます。
1点目も、2点目と同様に平均限界効果の算出の仕方が原因です。この原因の理解のための簡単な例として、が身長で
に体重が含まれ、身長と体重には相関があり、サンプルとしてAさん身長200cm体重90kg,Bさん150cm40kg,Cさん....がある場合を考えてみます。身長200cmについてのPDPlotの算出は、Aさん200cm90kg,B'さん「200cm」40kg,C'さん...という擬似的なサンプルを生み出して、それを機械学習モデルの入力として確率的平均を取ることでなされてしまいます。このように、機械学習モデルの学習データの身長体重の相関関係からしたらあり得ない(つまり、学習されていない)「200cm」40kgというサンプルが、PDPlotの値に寄与してしまっているのが問題です。
注意点
- 機会学習モデルの予測精度が十分高くなければ、そもそもPDPlotが正しくならない
- 現実世界での因果関係は必ずしも表さない
これらの原因は、PDPlotがモデルの出力をベースに算出していることです。そのため、これはPDPlot以外の解釈の手法でも同様に起きる問題です。
2点目はヒストグラムからこの問題が起きているか確認できます。
3点目について。よく使われるモデル(例えば決定木系のモデルや線形回帰などの統計モデルなど)では、そもそも特徴量と目的変数の因果関係を必ずしも表しません。そのため、そのPDPも特徴量と目的変数の因果関係を表しません。つまり、現実世界での因果関係は必ずしも表さない、ということです。
PDPlotのまとめ
PDPlotは、
- 対象特徴量の予測スコアへの(Globalな)平均限界効果を表す
- 平均限界効果の算出の仕方は、「他特徴量の分布を、対象特徴量の分布と独立に考えて確率平均を取ること」で見積もっている
理解するためには、定義をよく観察する必要があります。
参照
Interpretability Methods in Machine Learning: A Brief Survey - Two Sigma
非常におすすめです。本記事は、上記内容を自分なりにまとめ直したものです。
生き残るビジネスモデルとは
事業の構築、運営に必要な要素は、以下の4つに分類できます。 これらのうち1つ(あるいは複数)を根本から刷新することで、新しい仕組みが生まれてきます。
ヒト:新たな企業や業界、人を巻き込む
モノ:物の本質的な価値を再定義する
カネ:これまでお金にならなかった、新たなお金の流れをつくる
ただ、新しい仕組みを作っても、将来的に生き残れるビジネスモデルでないと、いづれ事業が終わってしまいます。では生き残るビジネスモデルであるために、重要なことは何でしょうか。 重要ワードは、以下の3点です。
創造性➡逆説の構造 社会性➡八方よし 経済性➡儲けの仕組み

1.創造性(逆説の構造)
①起点(事業領域)から定説(現状の当たり前のこと)をとらえる
②定説から逆説(異なる発想)を生み出す
※逆説は一つとは限らない
③逆説を起点と組み合わせる
↓
起点って普通、定説だよね
でも対象は逆で逆説なんだ

ポイント
逆説が非常識的であるほど、成り立たせることは高度な仕組みが必要で、成り立った時にはより価値がある
定説は移り変わっていく。なので時代の変化に合わせて何度も定説と逆説を繰り返し変化させていく必要がある
2.社会性(八方よし)
創造性や収益の仕組みが素晴らしくても、社会性が欠落していては、長続きはしない
ex)仕組みは画期的で収益が出ているが、環境汚染につながっているモデル
3.経済性(儲けの仕組み)
企業活動は、純資産と負債で集めた資金(B/S右側)を、資産(B/S左側)に変換することで、顧客に価値を提供し、結果的に利益を生む構造。つまりビジネスの根幹は資産への変換にある。
参考:ビジネス2.0図鑑
SQL Workbench/Jのインストール
SQL Workbench/Jは、フリーのSQLクライアントです。地味なやつですが抽出、集計に愛用してるので紹介します。
SQL Workbench/Jの特徴
うれしい点
- 動作が軽い(エディタ感覚で使える)
- インストーラー不要で使える(別環境へのコピーが簡単)
微妙な点
- 情報が少ない
- 名前が検索しにくい(MySQL Workbenchという別のやつが出てくる)
SQL Workbench/JはRedshift 専用ではない
SQL Workbench/J を使用してクラスターに接続する - Amazon Redshift
で接続例が紹介されているため、Redshiftの操作に利用している人が多いと思いますが、「DBMSに依存しない無料クロスプラットフォームSQLクエリツール」と記載されている通り、他のデータベース環境(DBMS)にも接続可能です。
ここでは、SQL Workbench/Jのインストールから、PostgreSQLに接続するまでの例を紹介します。
SQL Workbench/Jのインストール
環境
インストール
インストーラはありません。ダウンロードしたzipファイルを展開するだけで実行可能です。
「Generic package for all systems including all optional libraries」をダウンロードし、展開します。
実行
zipファイル展開先フォルダのSQLWorkbench64.exeを実行します。
Java(8以上)をインストールしていない場合や、インストール先を変更している場合は、Javaのインストールまたは、インストール先を指定する問い合わせが出ます。(Build126から)
Javaインストール先の手動設定
SQLWorkbench64.exeと同じフォルダにあるSQLWorkbench.cfgに、次の行を記載します。
[Workbench]
javaHome=<「bin」の1階層上のパス>
(例1) javaHome=C:\Program Files\Java\jre1.8.0_271
(例2) javaHome=C:\Program Files\AdoptOpenJDK\jdk-11.0.9.101-hotspot
PostgreSQLへの接続
SQL Workbench/J を使用してPostgreSQLに接続する - GRI Blog
TREASURE DATA(Presto)への接続
SQL Workbench/J を使用してTREASURE DATA(Presto)に接続する - GRI Blog