〜画像認識技術の進化を実感〜CNNの歴史Part1
いきなり雑談ですが、機械学習の分野では「最高精度」の意味で使われる言葉の1つが” State of the Art”であり、その略語がSoTAであることを最近知りました。
さて、先日はディープラーニング技術の近年の課題について書きました。
今回、本記事では、CNNモデルの研究開発の歴史を題材にしたいと思います。これまでに特に大きなインパクトを与えてきたCNNモデルをいくつか紹介します。各モデルの最善策や性能に着目しましょう。
まず簡単に、CNNとは
まだ馴染みを持たない方のために、簡単に説明します。ここでCNNは(米国のニュース報道局のことではなく)畳み込みニューラルネットワーク (Convolutional Neural Network)の慣用的な略称です。CNNは深いニューラルネットワーク(つまりディープラーニング)を用いた画像認識の最強力な手法であり、古典的な画像認識の手法よりもはるかに高精度を出せることが示されています。 ニューラルネットワークの初歩的な知識を手に入れたい方は先にこちらの優し〜い記事を読んでください! 【超優しいデータサイエンス・シリーズ】ニューラルネットワークの学習の仕組み - GRI Blog
CNNは、畳み込み層、最大プーリング層、全結合層の3種類のニューロン層から構成されています。
畳み込み層は、フィルタと画像データの間の畳み込み演算により特徴量を抽出し、特徴マップを形成する
プーリング層で、画像の些細な移動から予測への影響を減らすために情報圧縮を行う
畳み込み層とプーリング層は画像に対する「特徴抽出器」の役割
全結合層は抽出された特徴に基づいて分類の結果を出す「分類器」

入力層には、画像そのものを入力し 、ネットワークの前段で学習した結果を下流にある層に入力する処理を繰り返し、層が進むに従いますます高度な特徴を学習可能になります。入力層に近い層(浅い層)では、小領域の明暗など、画像全般に汎用的に存在する、単純かつ具体的な特徴を抽出します。中段層に進むと、輪郭や形などのもう少し高次な特徴を抽出します。出力層の近い深い層では、顔、眼、鼻などの複雑かつ抽象的な特徴を学習し、正しい認識結果へと導きます。
CNNを用いた画像認識技術の進歩
ディープラーニングが理論として初登場した1980年代以来、はじめて大きく注目されるようになったきっかけは、2012年に開催された画像認識の競技会ILSVRC(ImageNet Large Scale Visual Recognition Challenge)です。ILSVRCに参加した競技者たちは具体的には、画像に写っている物体のクラス(ラベル)を予測しようとします。順位を競うのは「精度(accuracy)」ではなく「誤差率」です。 従来では、パターン認識を得意とするサポートベクトルマシン(SVM)が画像認識分野の人気な機械学習手法でした。SVMを用いても毎年1~2%の改善しか出せませんでした。2012年に、トロント大学のヒントン教授のチームが開発したAlexNetというディープラーニング(CNN)を用いたモデルが勝利しました。何がすごいかというと、AlexNetは前年の誤差率を10%以上改善し、大規模画像認識コンテストにおけるCNNの初の成功例となりました。その実績は第3次AIブームの火付役となりました。 それ以降、ディープラーニングが画像認識の主流となりました。年々ますます優秀なアルゴリズムが開発されていき、2015年に、ResNetがヒトの認識の限界と言われる誤差率5%よりも低い値に達しました。
ILSVRCでは、画像認識モデルを学習するために、大規模データベース ImageNet からの学習データを用いています。ImageNetの画像データのボリュームはどれくらいかというと、クラスの種類は2万以上、画像数は1400万枚を超えるほどです。画像に写っている物体にはラベル(クラス名)が付与されています。クラス名に関して、WordNetという概念辞書を参照することで上位語、下位語の概念を取り入れています。例えば、「あやめ」の上位語は「花」です。 ImageNetの公式ウェブサイト:http://www.image-net.org/index
当時は他にも有名な画像認識用データセットが存在していました。例えば、MNISTは手書き数字(0-9)、Fashion MNISTは衣服、バッグ、靴などの白黒画像であり、どちらもクラス数が10個、データ数は数万枚です。CIFAR-10は動物や乗り物などのカラー画像であり、こちらもクラス数が10個、データ数は数万枚です。ImageNetはクラス種類も画像数も桁違いに大きいということがお分かりでしょう。
歴史的に有名なCNNモデル
■LeNet
1998年にYann LeCun氏(現Facebook AI Research)によって提案されました。CNNの元祖となるネットワークとして認識されています。その構成はまさにCNNの基本形状である畳込み層とプーリング層を交互に重ねたネットワークです。
■AlexNet
前述のように、2012年に発表され、ILSVRC2012で飛躍的な成績を残すことによってディープラーニングのブームをもたらしました。14層のネットワークになっており、ドロップアウト、データ拡張、バッチ正規化など数々のテクニックを取り入れています。 参考:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
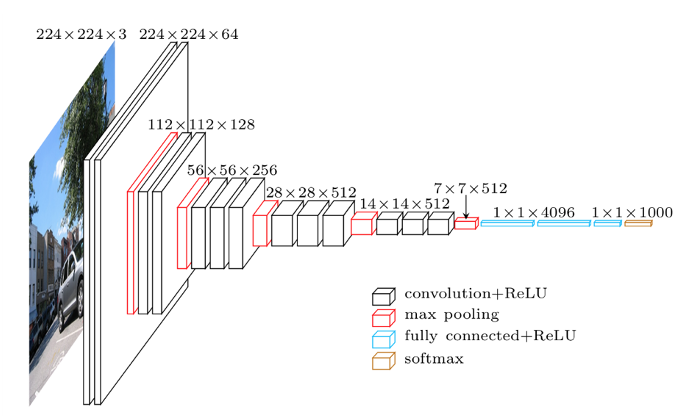
■VGG
オックスフォード大学のVGG(Visual Geometry Group)チームによって開発され、2014年のILSVRCで2位の成績を収めました(この時に1位は後述のGoogLeNet)。下図のように驚くほどシンプルなアーキテクチャだったため、その後も汎用的に使いやすいモデルとして人気が続いていました。AlexNetと同様に同じく畳み込み層とプーリング層を重ねた「普通の」CNNですが、AlexNetよりもネットワークを深くしています。重みを持つ隠れ層(畳み込み層や全結合層)が16層あるバージョンは「VGG-16」、隠れ層が19層あるのは「VGG-19」と名付けられています。 当時は経験則的に、大きいフィルターで画像を一気に畳み込むよりも、小さいフィルターを何個も畳み込む(=層を深くする)方が特徴をより良く抽出でき、高い表現力を出せることが知られるようになりました。この経験則に従い、VGGでは小さなフィルターを使った畳み込み層を2つから4つ連続して重ね、その間にプーリング層でサイズを半分にするのを繰り返すような構造をとります。 参考:Karen Simonyan and Andrew Zisserman(2014):Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556[cs](September 2014).
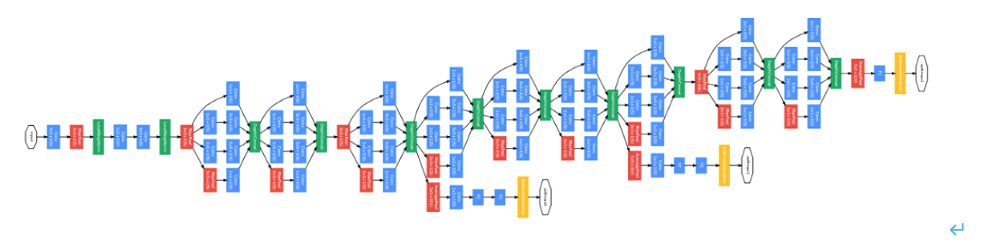
■GoogleNet
Googleによって開発され、2014年のILSVRCで1位になったモデルです。通常のCNNと異なる点は、入力層から出力層まで一直線ではなく、異なるサイズの畳み込み層を並列に並べたインセプション(Inception)モジュールを組み合わせた、横に広がりを持つ構造になっていることです(下図)。また、畳み込み処理の後に全結合層の代わりにGlobal Average Poolingを導入しています。これらの工夫により高い表現力を維持しつつ、過学習を抑え、学習パラメータ数を減らす効果があります。さらに、ネットワークの中間で分岐させて、その時点での損失情報のフィードバックを得る「Auxiliary classifier」を用います。GoogleNetは「インセプションモデル」とも呼ばれ、その改良版に Inception-v3、Inception-v4、Inception-ResNet などがあります。 参考:https://arxiv.org/pdf/1409.4842.pdf
本記事のPart2では、はじめてヒトの認識精度を超えたResNetとCNNの効率的なスケールアップのメソッドを取り入れることで高精度(SoTA)を達成しつつ、パラメータ数も大きく減らせたEfficiencyNetについて紹介します。
担当者: (分析官・講師)ヤン